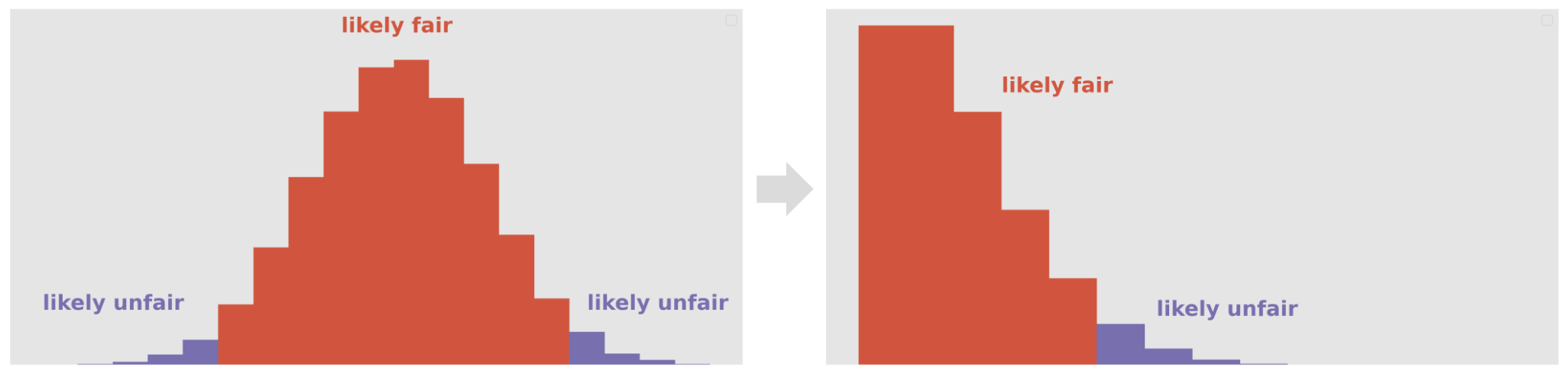
This means that the histogram above is divided into three regions, where two of them mean the same thing (we think our coin is unfair).
It would be a bit simpler if we had a histogram that was divided into just two regions. How do we create such a histogram?