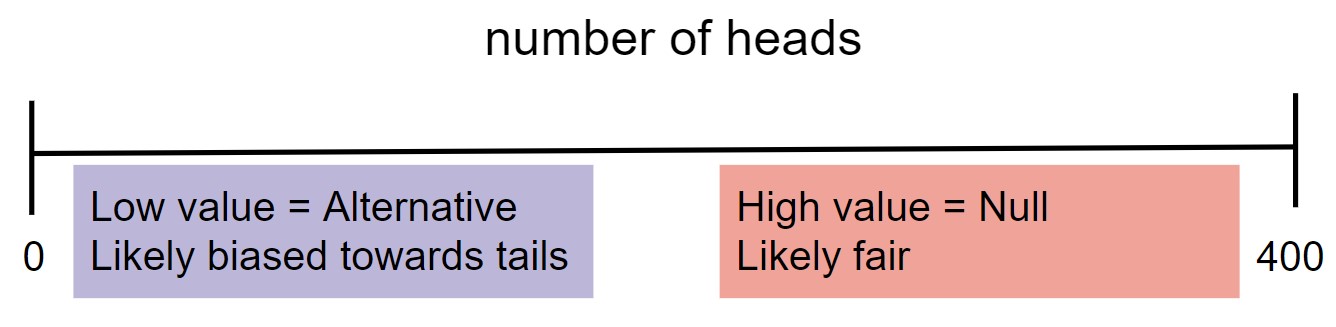
Final Project released, due Tuesday 12/5 at 11:59PM¶
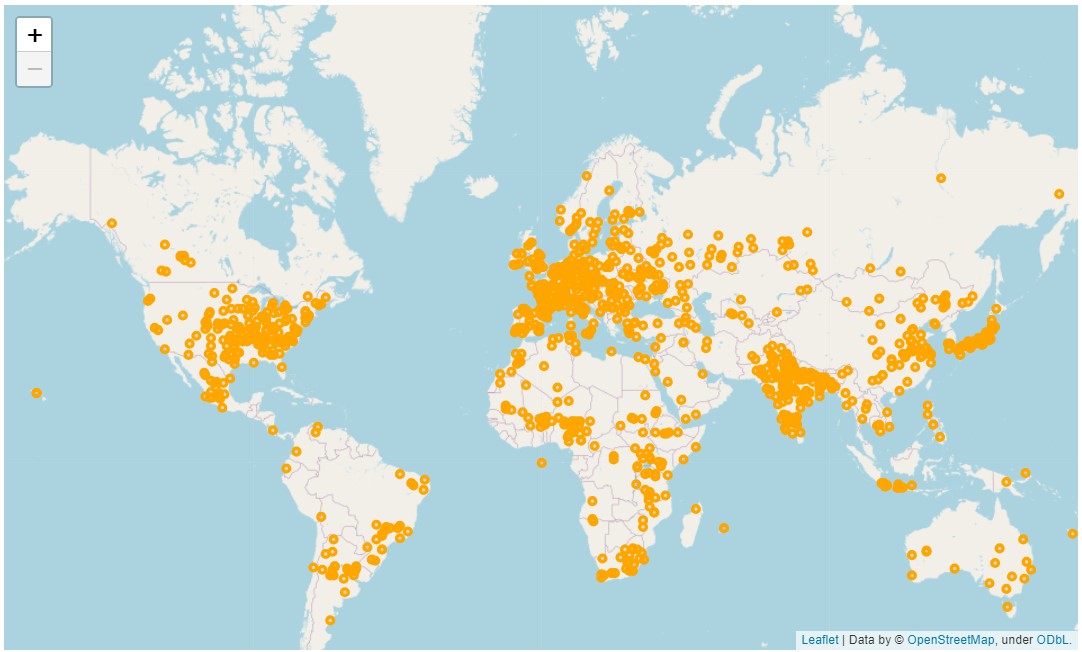
- In the project, you'll explore data from NASA about meteorites. You'll look at where meteorites landed and where they were seen falling, and explore whether there is any relationship between these locations and the locations where people tend to live. For example, here are the places where meteorites have been seen falling.
- If you want to work with a partner, follow these guidelines and get started soon!