- When choosing between "the coin is fair" and "the coin is not fair", we might select $|\text{number of heads} - 200 |.$

# Run this cell to set up packages for lecture.
from lec20_imports import *
Last time we looked at an example where we found a coin on the ground, flipped it 400 times, and used the results to determine whether the coin was likely fair.
# The results of our 400 flips.
flips_400 = bpd.read_csv('data/flips-400.csv')
flips_400.groupby('outcome').count()
| flip | |
|---|---|
| outcome | |
| Heads | 188 |
| Tails | 212 |
Question: Does our coin look like a fair coin, or not?
How "weird" is it to flip a fair coin 400 times and see only 188 heads?
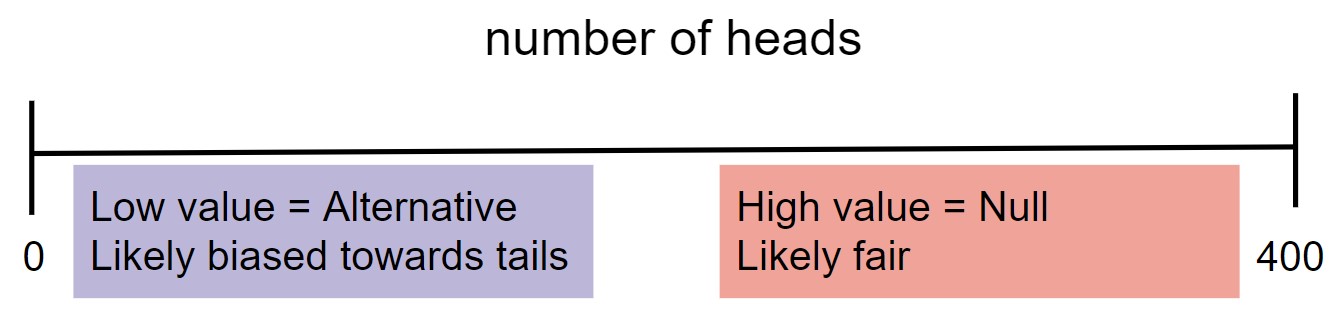
The test statistic you choose depends heavily on the pair of hypotheses you are testing. That said, these general guidelines may help.
# Computes a single simulated test statistic.
np.random.multinomial(400, [0.5, 0.5])[0]
185
# Computes 10,000 simulated test statistics.
np.random.seed(8)
results = np.array([])
for i in np.arange(10000):
result = np.random.multinomial(400, [0.5, 0.5])[0]
results = np.append(results, result)
results
array([207., 205., 207., ..., 192., 183., 224.])
Let's visualize the empirical distribution of the test statistic $\text{number of heads}$.
bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.legend();

bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.legend();
np.percentile(results, 5)
184.0
draw_cutoff(results)

bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.legend();
np.count_nonzero(results <= 170) / len(results)
0.0015
np.count_nonzero(results <= 195) / len(results)
0.3211
bpd.DataFrame().assign(results=results).plot(kind='hist', bins=np.arange(160, 240, 4),
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of the Number of Heads in 400 Flips of a Fair Coin');
plt.axvline(188, color='black', linewidth=4, label='observed statistic (188)')
plt.legend();

np.count_nonzero(results <= 188) / len(results)
0.125
>= or <= because it includes the probability that the test statistic exactly equals the observed statistic.# Midterm scores from DSC 10, Fall 2022, slightly perturbed for anonymity.
scores = bpd.read_csv('data/fa22-midterm-scores.csv')
scores
| Section | Score | |
|---|---|---|
| 0 | A | 54.5 |
| 1 | D | 62.0 |
| 2 | B | 23.5 |
| ... | ... | ... |
| 390 | C | 62.5 |
| 391 | B | 47.5 |
| 392 | D | 72.5 |
393 rows × 2 columns
scores.plot(kind='hist', density=True, figsize=(10, 5), ec='w', bins=np.arange(10, 85, 5), title='Distribution of Midterm Exam Scores in DSC 10');

# Total number of students who took the exam.
scores.shape[0]
393
# Calculate the number of students in each section.
scores.groupby('Section').count()
| Score | |
|---|---|
| Section | |
| A | 117 |
| B | 115 |
| C | 108 |
| D | 53 |
# Calculate the average midterm score in each section.
scores.groupby('Section').mean()
| Score | |
|---|---|
| Section | |
| A | 51.54 |
| B | 49.48 |
| C | 46.17 |
| D | 50.88 |

section_size = scores.groupby('Section').count().get('Score').loc['C']
observed_avg = scores.groupby('Section').mean().get('Score').loc['C']
print(f'Section C had {section_size} students and an average midterm score of {observed_avg}.')
Section C had 108 students and an average midterm score of 46.1712962962963.
# Sample 108 students from the class, independent of section,
# and compute the average score.
scores.sample(int(section_size), replace=False).get('Score').mean()
48.666666666666664
averages = np.array([])
repetitions = 1000
for i in np.arange(repetitions):
random_sample = scores.sample(int(section_size), replace=False)
new_average = random_sample.get('Score').mean()
averages = np.append(averages, new_average)
averages
array([48.15, 48.55, 48.69, ..., 48.72, 48.11, 48.89])
observed_avg
46.1712962962963
bpd.DataFrame().assign(RandomSampleAverage=averages).plot(kind='hist', bins=20,
density=True, ec='w', figsize=(10, 5),
title='Empirical Distribution of Midterm Averages for 108 Randomly Selected Students')
plt.axvline(observed_avg, color='black', linewidth=4, label='observed statistic')
plt.legend();

# p-value
np.count_nonzero(averages <= observed_avg) / repetitions
0.002
The p-value is below the standard cutoff of 0.05, and even below the 0.01 cutoff for being "highly statistically significant" so we reject the null hypothesis. It's not looking good for you, Suraj!
Recall the jury panel selection process:
Section 197 of California's Code of Civil Procedure says,
"All persons selected for jury service shall be selected at random, from a source or sources inclusive of a representative cross section of the population of the area served by the court."
jury = bpd.DataFrame().assign(
Ethnicity=['Asian', 'Black', 'Latino', 'White', 'Other'],
Eligible=[0.15, 0.18, 0.12, 0.54, 0.01],
Panels=[0.26, 0.08, 0.08, 0.54, 0.04]
)
jury
| Ethnicity | Eligible | Panels | |
|---|---|---|---|
| 0 | Asian | 0.15 | 0.26 |
| 1 | Black | 0.18 | 0.08 |
| 2 | Latino | 0.12 | 0.08 |
| 3 | White | 0.54 | 0.54 |
| 4 | Other | 0.01 | 0.04 |
What do you notice? 👀
jury.plot(kind='barh', x='Ethnicity', figsize=(10, 5));

with_diffs = jury.assign(Difference=(jury.get('Panels') - jury.get('Eligible')))
with_diffs
| Ethnicity | Eligible | Panels | Difference | |
|---|---|---|---|---|
| 0 | Asian | 0.15 | 0.26 | 0.11 |
| 1 | Black | 0.18 | 0.08 | -0.10 |
| 2 | Latino | 0.12 | 0.08 | -0.04 |
| 3 | White | 0.54 | 0.54 | 0.00 |
| 4 | Other | 0.01 | 0.04 | 0.03 |
with_abs_diffs = with_diffs.assign(AbsoluteDifference=np.abs(with_diffs.get('Difference')))
with_abs_diffs
| Ethnicity | Eligible | Panels | Difference | AbsoluteDifference | |
|---|---|---|---|---|---|
| 0 | Asian | 0.15 | 0.26 | 0.11 | 0.11 |
| 1 | Black | 0.18 | 0.08 | -0.10 | 0.10 |
| 2 | Latino | 0.12 | 0.08 | -0.04 | 0.04 |
| 3 | White | 0.54 | 0.54 | 0.00 | 0.00 |
| 4 | Other | 0.01 | 0.04 | 0.03 | 0.03 |
The Total Variation Distance (TVD) of two categorical distributions is the sum of the absolute differences of their proportions, all divided by 2.
with_abs_diffs
| Ethnicity | Eligible | Panels | Difference | AbsoluteDifference | |
|---|---|---|---|---|---|
| 0 | Asian | 0.15 | 0.26 | 0.11 | 0.11 |
| 1 | Black | 0.18 | 0.08 | -0.10 | 0.10 |
| 2 | Latino | 0.12 | 0.08 | -0.04 | 0.04 |
| 3 | White | 0.54 | 0.54 | 0.00 | 0.00 |
| 4 | Other | 0.01 | 0.04 | 0.03 | 0.03 |
with_abs_diffs.get('AbsoluteDifference').sum() / 2
0.14
def total_variation_distance(dist1, dist2):
'''Computes the TVD between two categorical distributions,
assuming the categories appear in the same order.'''
return np.abs((dist1 - dist2)).sum() / 2
jury.plot(kind='barh', x='Ethnicity', figsize=(10, 5))
plt.annotate('If you add up the total amount by which the blue bars\n are longer than the red bars, you get 0.14.', (0.08, 3.9), bbox=dict(boxstyle="larrow,pad=0.3", fc="#e5e5e5", ec="black", lw=2));
plt.annotate('If you add up the total amount by which the red bars\n are longer than the blue bars, you also get 0.14!', (0.23, 0.9), bbox=dict(boxstyle="larrow,pad=0.3", fc="#e5e5e5", ec="black", lw=2));

What is the TVD between the distributions of class standing in DSC 10 and DSC 40A?
| Class Standing | DSC 10 | DSC 40A |
|---|---|---|
| Freshman | 0.45 | 0.15 |
| Sophomore | 0.35 | 0.35 |
| Junior | 0.15 | 0.35 |
| Senior+ | 0.05 | 0.15 |
Note: np.random.multinomial creates samples drawn with replacement, even though real jury panels would be drawn without replacement. However, when the sample size (1453) is small relative to the population (number of people in Alameda County), the resulting distributions will be roughly the same whether we sample with or without replacement.
eligible = jury.get('Eligible')
sample_distribution = np.random.multinomial(1453, eligible) / 1453
sample_distribution
array([0.14, 0.18, 0.13, 0.54, 0.01])
total_variation_distance(sample_distribution, eligible)
0.01547143840330351
tvds = np.array([])
repetitions = 10000
for i in np.arange(repetitions):
sample_distribution = np.random.multinomial(1453, eligible) / 1453
new_tvd = total_variation_distance(sample_distribution, eligible)
tvds = np.append(tvds, new_tvd)
observed_tvd = total_variation_distance(jury.get('Panels'), eligible)
bpd.DataFrame().assign(tvds=tvds).plot(kind='hist', density=True, bins=20, ec='w', figsize=(10, 5),
title='Empirical Distribution of TVD Between Eligible Population and Random Sample')
plt.axvline(observed_tvd, color='black', linewidth=4, label='Observed Statistic')
plt.legend();

np.count_nonzero(tvds >= observed_tvd) / repetitions
0.0
jury.assign(RandomSample=sample_distribution).plot(kind='barh', x='Ethnicity', figsize=(10, 5),
title = "A Random Sample is Usually Similar to the Eligible Population");

