Graphs
Graph.javaDigraph.javaBreadthFirstPaths.javaDepthFirstPaths.java
Graph data types and traversal algorithms.
- Trace and explain each data structure in BFS and DFS graph traversal.
- Analyze the runtime of a graph algorithm in terms of vertices and edges.
- Define an appropriate graph abstraction for a given image processing problem.
Most of the data structures we’ve seen so far organize elements according to the properties of data in order to implement abstract data types like sets, maps, and priority queues.
- Search trees use the properties of an element to determine where it belongs in the search tree. In
TreeSetandTreeMap, the ordering relation is defined by the key’scompareTo. - Binary heaps compare the given priority values to determine whether to sink or swim a node in the heap. In
PriorityQueue, the priority values are also defined by the key’scompareTo. - Hash tables use the properties of an element to determine the hash code for the it, which then becomes a bucket index. In
HashSetandHashMap, the hash function is defined by the key’shashCode.
All these data structures rely on properties of data to achieve efficiency. Checking if an element is stored in a balanced search tree containing 1 billion elements only requires about 30 comparisons—which sure beats having to check all 1 billion elements in an unsorted array. This is only possible because (1) the compareTo method defines an ordering relation and (2) the balanced search tree maintains log N height for any assortment of N elements.
But if we step back, all of this happens within the internal implementation details of the balanced search tree. Clients or other users of a balanced search tree treat it as an abstraction, or a structure that they can use without knowing its implementation details. In fact, the client can’t assume any particular implementation because they’re writing their code against more general interfaces like Set, Map, or Autocomplete.
Graphs, however, represent a totally different kind of abstract data type with different goals. Rather than focus on enabling efficient access to data, graphs focus on representing client-defined relationships between data.
Although graphs may look like weirdly-shaped trees, they are used in very different situations. The greatest difference lies in how a graph is used by a client. Instead of only specifying the element to add in a graph, we often will also specify the edges or relationships between elements too. Much of the usefulness of a graph comes from the explicit relationships between elements.
For example, in Triton Maps, the MapGraph class represents all the streets and places around campus. Let’s focus on how data is represented in a graph.
public class MapGraph {
private final Map<Point, List<Edge<Point>>> neighbors;
}
Here’s a breakdown of the data type for the neighbors variable:
Map<Point, List<Edge<Point>>>- A map where the keys are unique
Pointobjects, and the values are the “neighbors” of eachPoint. Point- An object that has an x coordinate and a y coordinate. Each point can represent a physical place in the real world, like a street intersection.
List<Edge<Point>>- A list of edges to other points. Each key is associated with one list of values; in other words, each
Pointis associated with a list of neighboring points.
More generally, a graph is a data type composed of vertices and edges defined by the client. In Triton Maps, the vertices are unique Point objects while the edges are stretches of road connecting points. Street intersections are connected to other street intersections. Unlike lists, deques, sets, maps, and priority queues that are defined largely by how they organize elements, graphs are defined by vertices (nodes) and edges that define relationships between vertices.
In the real-world, most streets allow for travel in both directions. But there are also some one-way streets. Likewise, in a graph, undirected edges allow for movement in either direction whereas directed edges only allow movement in the specified direction.
Undirected graph abstract data type
An undirected graph (or simply “graph” without any qualifiers) is an abstract data type that contains zero or more vertices and zero or more undirected edges between pairs of vertices. The following slide1 describes some undirected graph terminology.
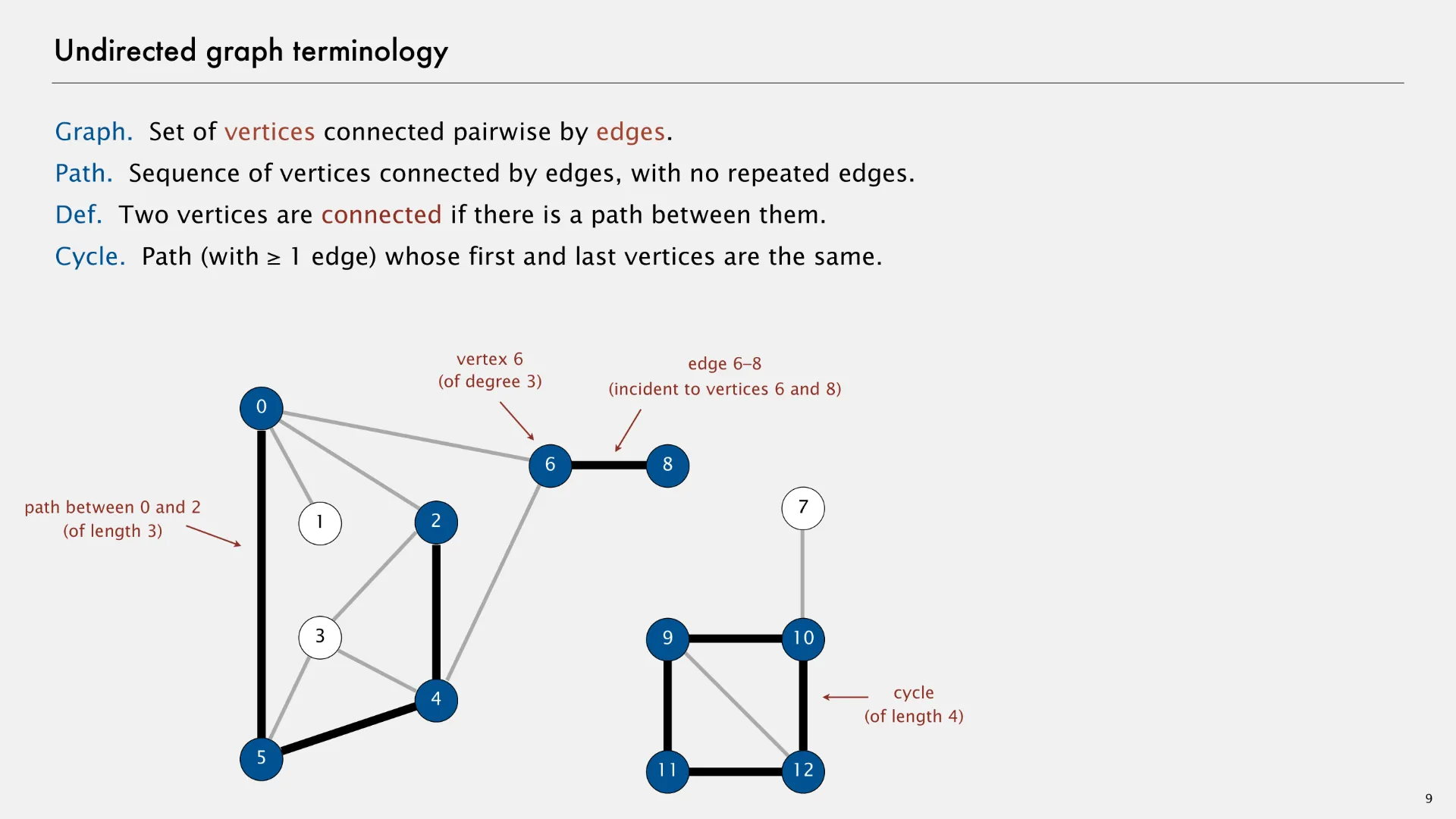
- Path
- Sequence of vertices connected by undirected edges, with no repeated edges.
- Two vertices are connected if there is a path between them.
- Cycle
- Path (with 1 or more edges) whose first and last vertices are the same.
- Degree
- Number of undirected edges associated with a given vertex.
An interface for an undirected graph could require an addEdge and neighbors method.
public interface UndirectedGraph<V> {
/** Add an undirected edge between vertices (v, w). */
public void addEdge(V v, V w);
/** Returns a list of the edges adjacent to the given vertex. */
public List<Edge<V>> neighbors(V v);
}
Directed graph abstract data type
A directed graph (or “digraph”) is an abstract data type that contains zero or more vertices and zero or more directed edges between pairs of vertices. The following slide1 describes some directed graph terminology.
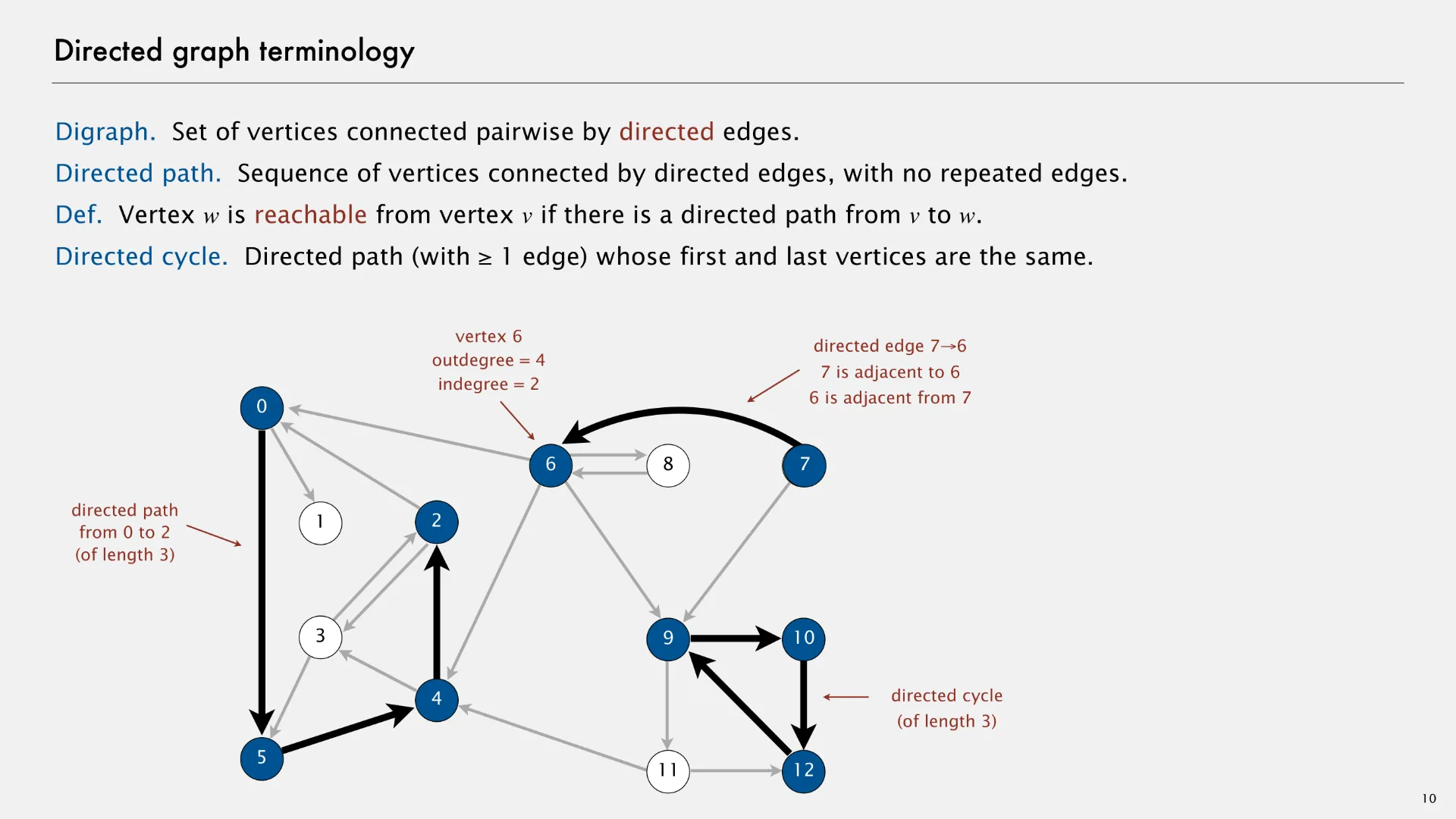
Although parallel (duplicate) edges are not allowed, a directed graph can have edges in both directions between each pair of nodes. In the example above, note there are edges (2, 3) and (3, 2), as well as edges (6, 8) and (8, 6). These two pairs of edges allow for movement in both directions.
- Directed path
- Sequence of vertices connected by directed edges, with no repeated edges.
- Vertex w is reachable from vertex v if there is a directed path from v to w.
- Directed cycle
- Directed path (with 1 or more edges) whose first and last vertices are the same.
- Outdegree
- Number of directed edges outgoing from a given vertex.
- Indegree
- Number of directed edges incoming to the given vertex.
An interface for an directed graph could also require an addEdge and neighbors method, just as in the undirected graph example.
public interface DirectedGraph<V> {
/** Add an directed edge between vertices (v, w). */
public void addEdge(V v, V w);
/** Returns a list of the outgoing edges from the given vertex. */
public List<Edge<V>> neighbors(V v);
}
Adjacency lists data structure
Adjacency lists is a data structure for implementing both undirected graphs and directed graphs. MapGraph uses an adjacency lists data structure: the neighbors map associates each Point with a List<Edge<Point>>. The adjacency lists provides a very direct implementation of the DirectedGraph interface methods like addEdge and neighbors.
public class MapGraph implements DirectedGraph<Point> {
private final Map<Point, List<Edge<Point>>> neighbors;
/** Constructs a new map graph. */
public MapGraph(...) {
neighbors = new HashMap<>();
}
/** Adds a directed edge to this graph if it doesn't already exist using distance as weight. */
public void addEdge(Point from, Point to) {
if (!neighbors.containsKey(from)) {
neighbors.put(from, new ArrayList<>());
}
neighbors.get(from).add(new Edge<>(from, to, estimatedDistance(from, to)));
}
/** Returns a list of the outgoing edges from the given vertex. */
public List<Edge<Point>> neighbors(Point point) {
if (!neighbors.containsKey(point)) {
return new ArrayList<>();
}
return neighbors.get(point);
}
}
The MapGraph class doesn’t have a method for adding just a single vertex or getting a list of all the vertices or all the edges. These aren’t necessary for Triton Maps. But in other situations, you might like having these methods that provide different functionality. The Java developers did not provide a standard Graph interface like they did for List, Set, or Map because graphs are often custom-designed for specific problems. What works for Triton Maps might not work well for other graph problems.
There are many options for Map and Set implementations. Instead of HashMap, we could have chosen TreeMap; instead of HashSet, TreeSet. However, we’ll often visualize adjacency lists by drawing the map as an array associating each vertex with a linked list representing its neighbors. The following graph visualization1 on the left matches with the data structure visualization on the right, with the edge (6, 9) marked red in both the left and the right side.
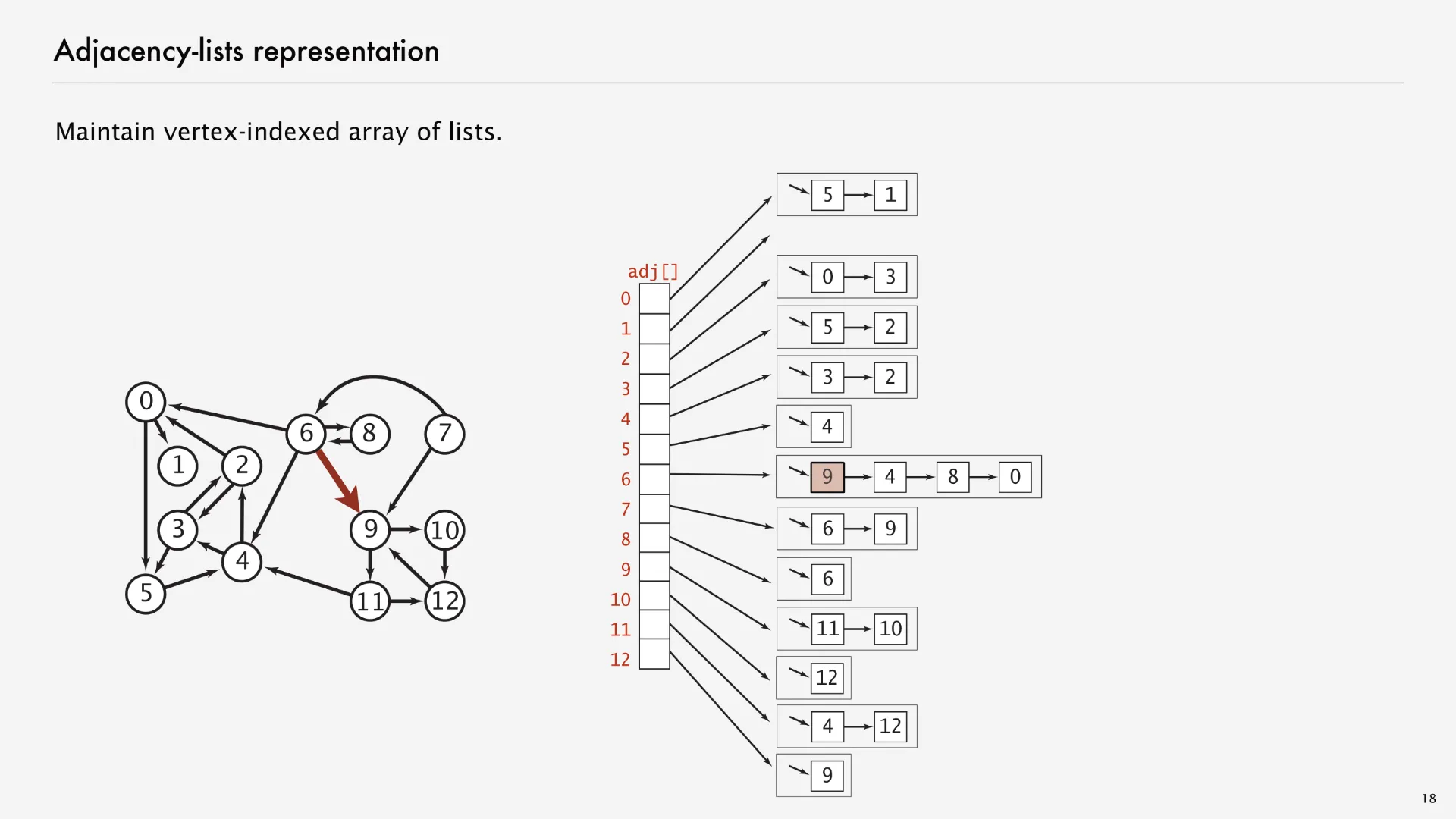
Adjacency lists aren’t the only way to implement graphs. Two other common approaches are adjacency matrices and edge sets. Both of these approaches provide different affordances (making some graph methods easier to implement or more efficient in runtime), but adjacency lists are still the most popular option for the graph algorithms we’ll see in this class. Keith Schwarz writes on StackOverflow about a few graph problems where you might prefer using an adjacency matrix over an adjacency list but summarizes at the top:
Adjacency lists are generally faster than adjacency matrices in algorithms in which the key operation performed per node is “iterate over all the nodes adjacent to this node.” That can be done in time O(deg(v)) time for an adjacency list, where deg(v) is the degree of node v, while it takes time Θ(n) in an adjacency matrix. Similarly, adjacency lists make it fast to iterate over all of the edges in a graph—it takes time O(m + n) to do so, compared with time Θ(n2) for adjacency matrices.
Some of the most-commonly-used graph algorithms (BFS, DFS, Dijkstra’s algorithm, A* search, Kruskal’s algorithm, Prim’s algorithm, Bellman-Ford, Karger’s algorithm, etc.) require fast iteration over all edges or the edges incident to particular nodes, so they work best with adjacency lists.
Graph Traversals
How do we use a graph to solve problems like computing navigation directions? Before we can discuss graph algorithms, we’ll need a way to traverse a graph or explore all of its data. To traverse a tree, we can start from the overall root and recursively work our way down. To traverse a hash table, we can start from bucket index 0 and iterate over all the separate chains. But for a graph, where do we start the traversal?
By applying the recursive tree traversal idea, we discovered a graph algorithm called depth-first search (DFS). Depth-first search isn’t the only graph traversal algorithm, and it’s often compared to another graph traversal algorithm called breadth-first search (BFS). BFS will be the template for many of the graph algorithms that we’ll learn in the coming lessons.
- Breadth-first search (BFS)
- An iterative graph traversal algorithm that expands outward, level-by-level, from a given
startvertex.void bfs(Graph<V> graph, V start) { Queue<V> perimeter = new ArrayDeque<>(); Set<V> visited = new HashSet<>(); perimeter.add(start); visited.add(start); while (!perimeter.isEmpty()) { V from = perimeter.remove(); // Process the current vertex by printing it out System.out.println(from); for (Edge<V> edge : graph.neighbors(from)) { V to = edge.to; if (!visited.contains(to)) { perimeter.add(to); visited.add(to); } } } } - Depth-first search (DFS)
- A recursive graph traversal algorithm that explores as far as possible from a given
startvertex until it reaches a base case and needs to backtrack.void dfs(Graph<V> graph, V start) { dfs(graph, start, new HashSet<>()); } dfs(Graph<V> graph, V from, Set<V> visited) { // Process the current vertex by printing it out System.out.println(from); visited.add(from); for (Edge<V> edge : graph.neighbors(from)) { V to = edge.to; if (!visited.contains(to)) { dfs(graph, to); } } }
BFS and DFS represent two ways of traversing over all the data in a graph by visiting all the vertices and checking all the edges. BFS and DFS are like the for loops of graphs: on their own, they don’t solve a specific problem, but they are an important building block for graph algorithms.
BFS provides a lot more utility than DFS in this context because it can be used to find the shortest paths in a unweighted graph with the help of two extra data structures called edgeTo and distTo.
Map<V, Edge<V>> edgeTomaps each vertex to the edge used to reach it in the BFS traversal.Map<V, Integer> distTomaps each vertex to the number of edges from thestartvertex.
Problems and solutions
Whereas sets, maps, and priority queues emphasize efficient access to elements, graphs emphasize not only elements (vertices) but also the relationships between elements (edges). The efficiency of a graph data structure depends on the underlying data structures used to represent its vertices and edges. But there’s another way to understand graphs through the lens of computational problems and algorithmic solutions.
- Computational problem
- An abstract problem that can be represented, formalized, and/or solved using algorithms.
- In Java, we often represent problems using interfaces describing expected functionality.
Sorting is the problem of rearranging elements according to an ordering relation (via comparison). Sets are an example of an abstract data type that represents a collection of unique elements. Graph traversal is the problem of visiting/checking/processing each vertex in a graph.
- Algorithmic solution
- A a sequence of steps or description of process that can be used to solve computational problems.
- In Java, we often represent solutions using classes detailing how to implement functionality.
Insertion sort, selection sort, and merge sort are algorithms for sorting. Search trees and hash tables are algorithms for implementing sets. BFS and DFS are algorithms for graph traversal.
This relationships suggests that problems like graph search can be represented using interfaces, which are then implemented by solutions that are represented using classes. In Triton Maps, the graphs.shortestpaths package includes interfaces and classes for finding the shortest paths in a directed graph.
public interface ShortestPathSolver<V>
public class DijkstraSolver<V> implements ShortestPathSolver<V>
public class BellmanFordSolver<V> implements ShortestPathSolver<V>
public class ToposortDAGSolver<V> implements ShortestPathSolver<V>
Each of these graph algorithms—Dijkstra’s algorithm, Bellman-Ford algorithm, and the toposort-DAG algorithm—do most of their work in the class constructor. If we wanted to add a BFS algorithm to this list, it would take the bfs method defined above and do most of the work inside of the constructor.
public class BreadthFirstSearch<V> {
private final Map<V, Edge<V>> edgeTo;
private final Map<V, Integer> distTo;
public BreadthFirstSearch(Graph<V> graph, V start) {
edgeTo = new HashMap<>();
distTo = new HashMap<>();
Queue<V> perimeter = new ArrayDeque<>();
Set<V> visited = new HashSet<>();
perimeter.add(start);
visited.add(start);
edgeTo.put(start, null);
distTo.put(start, 0);
while (!perimeter.isEmpty()) {
V from = perimeter.remove();
for (Edge<V> edge : graph.neighbors(from)) {
V to = edge.to;
if (!visited.contains(to)) {
edgeTo.put(to, edge);
distTo.put(to, distTo.get(from) + 1);
perimeter.add(to);
visited.add(to);
}
}
}
}
/** Returns the unweighted shortest path from the start to the goal. */
public List<V> solution(V goal) {
List<V> path = new ArrayList<>();
V curr = goal;
path.add(curr);
while (edgeTo.get(curr) != null) {
curr = edgeTo.get(curr).from;
path.add(curr);
}
Collections.reverse(path);
return path;
}
}
The solution method begins at goal and uses edgeTo to trace the path back to start.
There are hundreds of problems and algorithms for solving them. The field of graph theory investigates these graph problems and graph algorithms.
Robert Sedgewick and Kevin Wayne. 2020. Graphs and Digraphs. ↩ ↩2 ↩3