import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = (10, 5)
import util
In addition to the instructor, we have several other course staff members who are here to support you in discussion, office hours, and Campuswire.
Learn more about them at dsc80.com/staff.
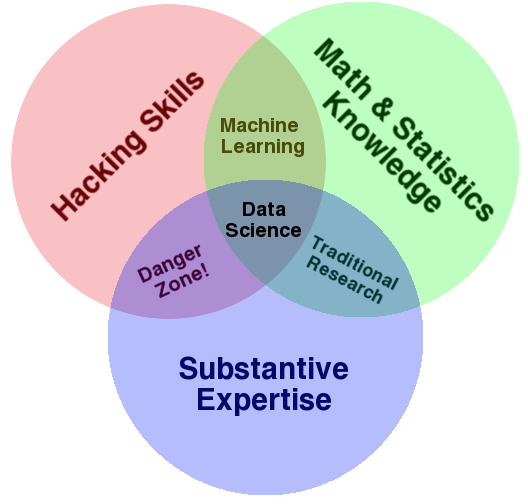
In DSC 10, we told you that science is about drawing useful conclusions from data using computation.
Let's look at some other definitions.
There isn't agreement on which "Venn Diagram" is correct!
In 2016, O'Reilly administered a Data Scientice Salary Survey. Part of the survey asked self-identified data scientists what tasks they do on a regular basis.
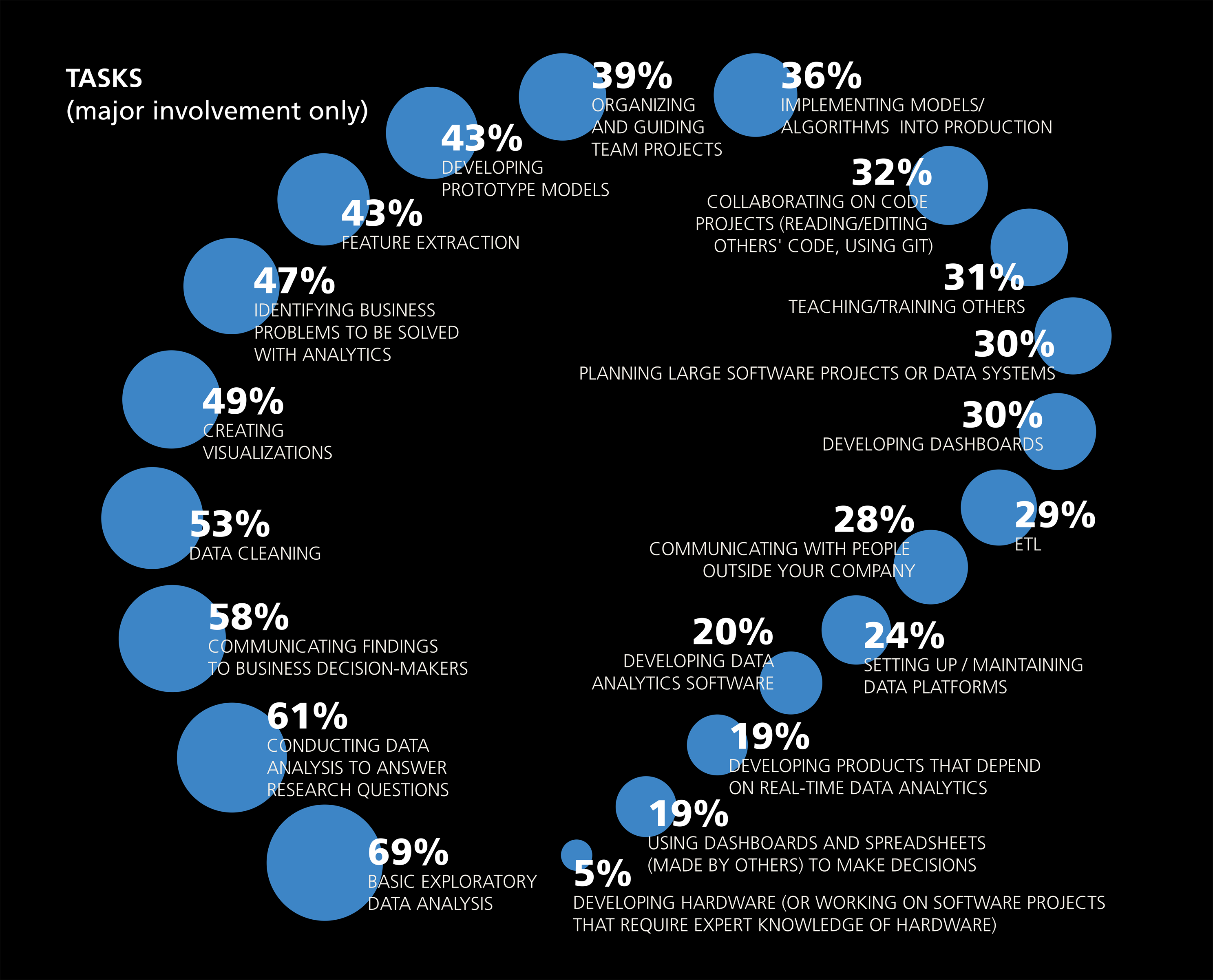
What do you notice?
My take: in DSC 80, and in the DSC major more broadly, we are equipping you to ask and answer questions using data.
Let's look at some examples of data science in practice.
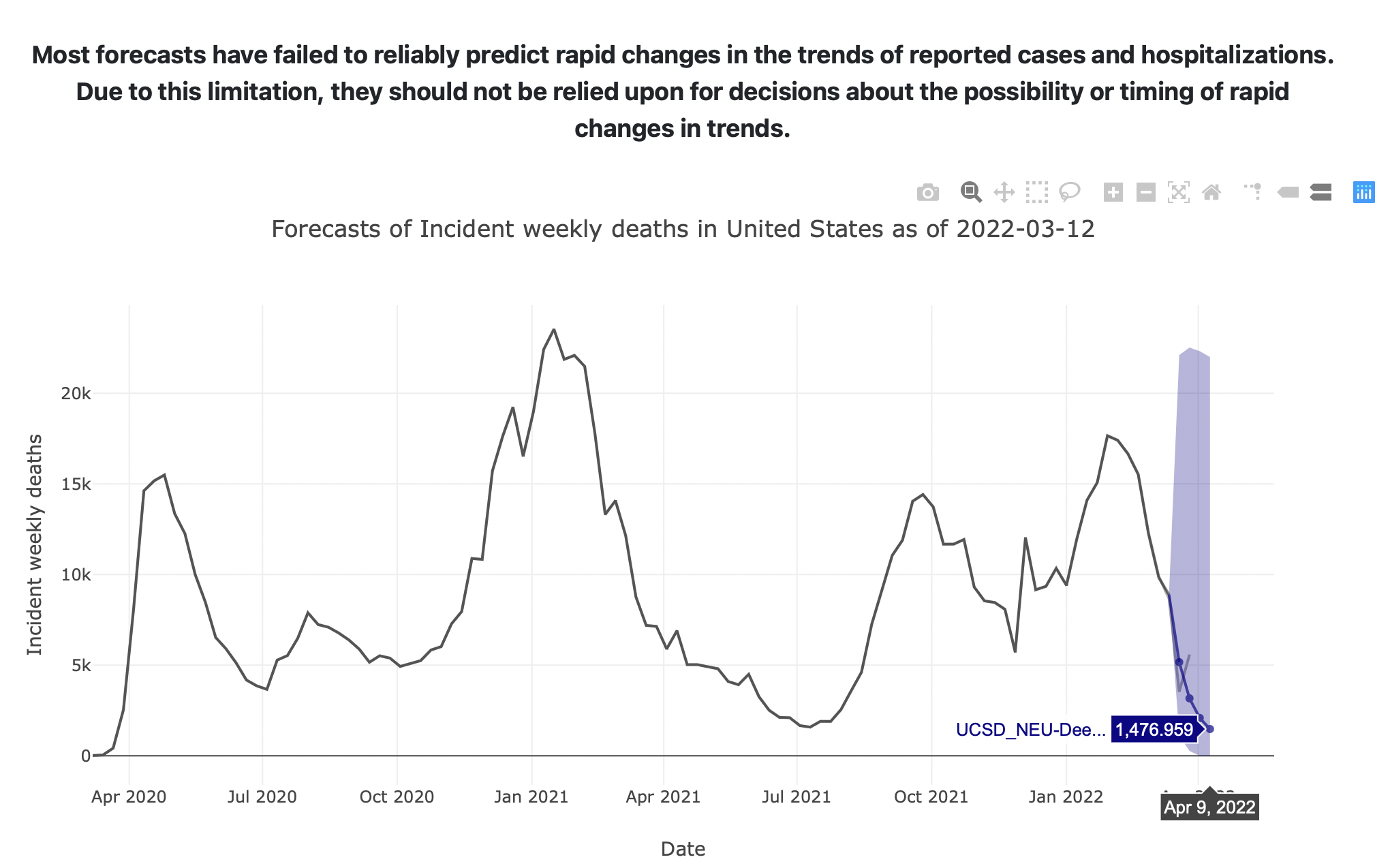
Evaluation of case forecasts showed that more reported cases than expected fell outside the forecast prediction intervals for extended periods of time. Given this low reliability, COVID-19 case forecasts will no longer be posted by the Centers for Disease Control and Prevention. - CDC.gov
A "Face Depixelizer" released in 2020 takes pixelated images and generates images that are perceptually realistic and downscale correctly.
What happened here? Why do you think this happened?
The decisions that we make as data scientists have the potential to impact the livelihoods of other people.
Good data analysis is not:
There are many tools out there for data science, but they are merely tools. They don’t do any of the important thinking – that's where you come in!
“The purpose of computing is insight, not numbers.” - R. Hamming. Numerical Methods for Scientists and Engineers (1962).
In this course, you will...
After this course, you will...
This course was desgined by a former data scientist at Amazon (Aaron Fraenkel). As such, you'll be learning skills that you need to know as a data scientist.
pandasscikit-learnIn addition, you must also fill out our Welcome + Alternate Exams Form.
You will access all course content by pulling the course GitHub repository:
We will post HTML versions of lecture notebooks on the course website, but otherwise you must pull from this repository to access all course materials (including blank copies of assignments).
In this course, you will learn by doing!
In DSC 80, assignments will usually consist of both a Jupyter Notebook and a .py file. You will write your code in the .py file; the Jupyter Notebook will contain problem descriptions and test cases. Lab 1 will explain the workflow.
babypandas.It is no secret that this course requires a lot of work - becoming fluent with working with data is hard!
Once you've tried to solve problems on your own, we're glad to help.
You learned about the scientific method in elementary school.

However, it hides a lot of complexity.
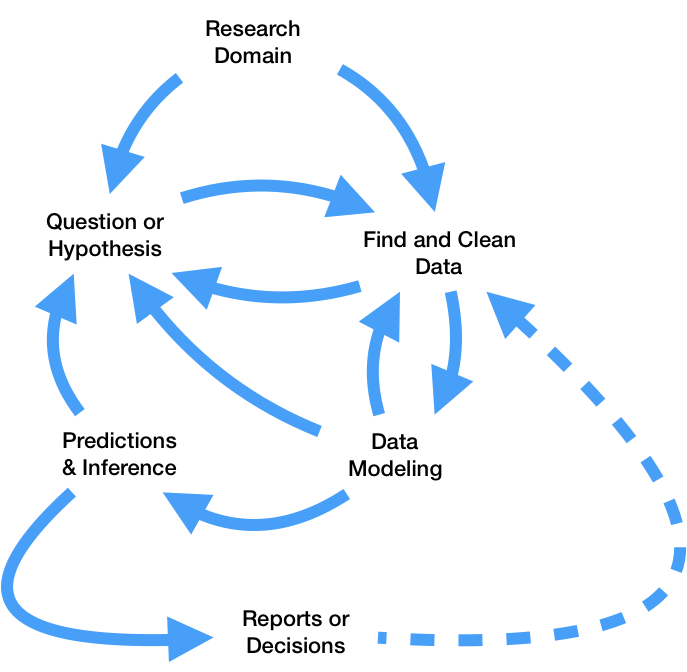
All steps lead to more questions!
We have our domain – City of San Diego employee salaries. What are some questions we might want to ask?
Why is this dataset relevant?
salary_path = util.safe_download('https://transcal.s3.amazonaws.com/public/export/san-diego-2020.csv')
salaries = pd.read_csv(salary_path)
util.anonymize_names(salaries)
salaries
| Employee Name | Job Title | Base Pay | Overtime Pay | Other Pay | Benefits | Total Pay | Total Pay & Benefits | Year | Notes | Agency | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Xxxx | Police Officer | 117691.0 | 187290.0 | 13331.00 | 36380.0 | 318312.0 | 354692.0 | 2020 | NaN | San Diego | FT |
| 1 | Gary Xxxx | Police Officer | 117691.0 | 160062.0 | 42946.00 | 31795.0 | 320699.0 | 352494.0 | 2020 | NaN | San Diego | FT |
| 2 | Eric Xxxx | Fire Engineer | 35698.0 | 204462.0 | 69121.00 | 38362.0 | 309281.0 | 347643.0 | 2020 | NaN | San Diego | PT |
| 3 | Gregg Xxxx | Retirement Administrator | 305000.0 | 0.0 | 12814.00 | 24792.0 | 317814.0 | 342606.0 | 2020 | NaN | San Diego | FT |
| 4 | Joseph Xxxx | Fire Battalion Chief | 94451.0 | 157778.0 | 48151.00 | 42096.0 | 300380.0 | 342476.0 | 2020 | NaN | San Diego | FT |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12600 | Elena Xxxx | Asst Eng-Civil | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT |
| 12601 | Gary Xxxx | Police Officer | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT |
| 12602 | Sara Xxxx | Asst Planner | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT |
| 12603 | Kevin Xxxx | Project Ofcr 1 | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT |
| 12604 | Deedrick Xxxx | Utility Worker 2 | 0.0 | 0.0 | 1.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT |
12605 rows × 12 columns
# .T is for transpose()
salaries.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| Base Pay | 12605.0 | 56066.707180 | 35773.864476 | 0.0 | 32714.0 | 54725.0 | 77512.0 | 305000.0 |
| Overtime Pay | 12605.0 | 8789.100198 | 18507.729611 | -293.0 | 0.0 | 588.0 | 9174.0 | 204462.0 |
| Benefits | 12605.0 | 15456.868068 | 11183.968318 | -39.0 | 6425.0 | 14549.0 | 22745.0 | 86066.0 |
| Total Pay | 12605.0 | 75181.321618 | 49634.174460 | 0.0 | 41177.0 | 71354.0 | 106903.0 | 320699.0 |
| Total Pay & Benefits | 12605.0 | 90638.189687 | 58833.565854 | 1.0 | 52478.0 | 86226.0 | 128147.0 | 354692.0 |
| Year | 12605.0 | 2020.000000 | 0.000000 | 2020.0 | 2020.0 | 2020.0 | 2020.0 | 2020.0 |
| Notes | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
'Overtime Pay' of -\$293!'Other Pay' column contained numbers, why doesn't it appear here?'Notes' column that is missing for everybody?Let's plot the distribution of salaries.
salaries['Total Pay'].plot(kind='hist', density=True, bins=50, ec='w',
title='City of San Diego Employee Salaries');

Which of the following best describe the distribution of San Diego employee salaries?
Let's draw the distribution of salaries separately for part-time and full-time employees.
bystatus = salaries.groupby('Status')
bystatus['Total Pay'].plot(kind='kde', title='City of San Diego Employee Salaries, Part-Time vs. Full-Time')
plt.legend(bystatus.groups);

salaries.head()
| Employee Name | Job Title | Base Pay | Overtime Pay | Other Pay | Benefits | Total Pay | Total Pay & Benefits | Year | Notes | Agency | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Xxxx | Police Officer | 117691.0 | 187290.0 | 13331.00 | 36380.0 | 318312.0 | 354692.0 | 2020 | NaN | San Diego | FT |
| 1 | Gary Xxxx | Police Officer | 117691.0 | 160062.0 | 42946.00 | 31795.0 | 320699.0 | 352494.0 | 2020 | NaN | San Diego | FT |
| 2 | Eric Xxxx | Fire Engineer | 35698.0 | 204462.0 | 69121.00 | 38362.0 | 309281.0 | 347643.0 | 2020 | NaN | San Diego | PT |
| 3 | Gregg Xxxx | Retirement Administrator | 305000.0 | 0.0 | 12814.00 | 24792.0 | 317814.0 | 342606.0 | 2020 | NaN | San Diego | FT |
| 4 | Joseph Xxxx | Fire Battalion Chief | 94451.0 | 157778.0 | 48151.00 | 42096.0 | 300380.0 | 342476.0 | 2020 | NaN | San Diego | FT |
salaries dataset to infer the gender of San Diego employees.names_path = util.safe_download('https://www.ssa.gov/oact/babynames/names.zip')
import pathlib
dfs = []
for path in pathlib.Path('data/names/').glob('*.txt'):
year = int(str(path)[14:18])
if year >= 1964:
df = pd.read_csv(path, names=['firstname', 'gender', 'count']).assign(year=year)
dfs.append(df)
names = pd.concat(dfs)
names
| firstname | gender | count | year | |
|---|---|---|---|---|
| 0 | Emily | F | 25957 | 2000 |
| 1 | Hannah | F | 23084 | 2000 |
| 2 | Madison | F | 19968 | 2000 |
| 3 | Ashley | F | 17997 | 2000 |
| 4 | Sarah | F | 17706 | 2000 |
| ... | ... | ... | ... | ... |
| 32025 | Zyheem | M | 5 | 2019 |
| 32026 | Zykel | M | 5 | 2019 |
| 32027 | Zyking | M | 5 | 2019 |
| 32028 | Zyn | M | 5 | 2019 |
| 32029 | Zyran | M | 5 | 2019 |
1399746 rows × 4 columns
We began compiling the baby name list in 1997, with names dating back to 1880. At the time of a child’s birth, parents supply the name to us when applying for a child’s Social Security card, thus making Social Security America’s source for the most popular baby names. Please share this with your friends and family—and help us spread the word on social media. - Social Security’s Top Baby Names for 2020
names¶'gender' in names are 'M' and 'F'.'M' and 'F'.names.head()
| firstname | gender | count | year | |
|---|---|---|---|---|
| 0 | Emily | F | 25957 | 2000 |
| 1 | Hannah | F | 23084 | 2000 |
| 2 | Madison | F | 19968 | 2000 |
| 3 | Ashley | F | 17997 | 2000 |
| 4 | Sarah | F | 17706 | 2000 |
# Get the count of each unique value in the 'gender' column
names['gender'].value_counts()
F 838442 M 561304 Name: gender, dtype: int64
# Look at a single name
names[names['firstname'] == 'Billy']
| firstname | gender | count | year | |
|---|---|---|---|---|
| 10875 | Billy | F | 8 | 2000 |
| 18042 | Billy | M | 670 | 2000 |
| 14851 | Billy | F | 6 | 2014 |
| 20007 | Billy | M | 287 | 2014 |
| 19912 | Billy | M | 281 | 2015 |
| ... | ... | ... | ... | ... |
| 18364 | Billy | M | 208 | 2020 |
| 21031 | Billy | M | 458 | 2008 |
| 14044 | Billy | F | 6 | 2018 |
| 18949 | Billy | M | 262 | 2018 |
| 18836 | Billy | M | 245 | 2019 |
104 rows × 4 columns
# Look at various summary statistics
names.describe()
| count | year | |
|---|---|---|
| count | 1.399746e+06 | 1.399746e+06 |
| mean | 1.459451e+02 | 1.996861e+03 |
| std | 1.194298e+03 | 1.542586e+01 |
| min | 5.000000e+00 | 1.964000e+03 |
| 25% | 7.000000e+00 | 1.985000e+03 |
| 50% | 1.100000e+01 | 1.999000e+03 |
| 75% | 3.000000e+01 | 2.010000e+03 |
| max | 8.529100e+04 | 2.020000e+03 |
'firstname' that describes the total number of 'F' and 'M' babies in names for each unique 'firstname'.counts_by_gender = (
names
.groupby(['firstname', 'gender'])
.sum()
.reset_index()
.pivot('firstname', 'gender', 'count')
.fillna(0)
)
counts_by_gender
| gender | F | M |
|---|---|---|
| firstname | ||
| Aaban | 0.0 | 120.0 |
| Aabha | 46.0 | 0.0 |
| Aabid | 0.0 | 16.0 |
| Aabidah | 5.0 | 0.0 |
| Aabir | 0.0 | 10.0 |
| ... | ... | ... |
| Zyvion | 0.0 | 5.0 |
| Zyvon | 0.0 | 7.0 |
| Zyyanna | 6.0 | 0.0 |
| Zyyon | 0.0 | 6.0 |
| Zzyzx | 0.0 | 10.0 |
91360 rows × 2 columns
counts_by_gender['F'] > counts_by_gender['M']
firstname
Aaban False
Aabha True
Aabid False
Aabidah True
Aabir False
...
Zyvion False
Zyvon False
Zyyanna True
Zyyon False
Zzyzx False
Length: 91360, dtype: bool
genders = counts_by_gender.assign(gender=np.where(counts_by_gender['F'] > counts_by_gender['M'], 'F', 'M'))
genders
| gender | F | M | gender |
|---|---|---|---|
| firstname | |||
| Aaban | 0.0 | 120.0 | M |
| Aabha | 46.0 | 0.0 | F |
| Aabid | 0.0 | 16.0 | M |
| Aabidah | 5.0 | 0.0 | F |
| Aabir | 0.0 | 10.0 | M |
| ... | ... | ... | ... |
| Zyvion | 0.0 | 5.0 | M |
| Zyvon | 0.0 | 7.0 | M |
| Zyyanna | 6.0 | 0.0 | F |
| Zyyon | 0.0 | 6.0 | M |
| Zzyzx | 0.0 | 10.0 | M |
91360 rows × 3 columns
'gender' column to salaries¶This involves two steps:
'Employee Name'.salaries and genders.# Add firstname column
salaries['firstname'] = salaries['Employee Name'].str.split().str[0]
salaries
| Employee Name | Job Title | Base Pay | Overtime Pay | Other Pay | Benefits | Total Pay | Total Pay & Benefits | Year | Notes | Agency | Status | firstname | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Xxxx | Police Officer | 117691.0 | 187290.0 | 13331.00 | 36380.0 | 318312.0 | 354692.0 | 2020 | NaN | San Diego | FT | Michael |
| 1 | Gary Xxxx | Police Officer | 117691.0 | 160062.0 | 42946.00 | 31795.0 | 320699.0 | 352494.0 | 2020 | NaN | San Diego | FT | Gary |
| 2 | Eric Xxxx | Fire Engineer | 35698.0 | 204462.0 | 69121.00 | 38362.0 | 309281.0 | 347643.0 | 2020 | NaN | San Diego | PT | Eric |
| 3 | Gregg Xxxx | Retirement Administrator | 305000.0 | 0.0 | 12814.00 | 24792.0 | 317814.0 | 342606.0 | 2020 | NaN | San Diego | FT | Gregg |
| 4 | Joseph Xxxx | Fire Battalion Chief | 94451.0 | 157778.0 | 48151.00 | 42096.0 | 300380.0 | 342476.0 | 2020 | NaN | San Diego | FT | Joseph |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12600 | Elena Xxxx | Asst Eng-Civil | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT | Elena |
| 12601 | Gary Xxxx | Police Officer | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT | Gary |
| 12602 | Sara Xxxx | Asst Planner | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Sara |
| 12603 | Kevin Xxxx | Project Ofcr 1 | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Kevin |
| 12604 | Deedrick Xxxx | Utility Worker 2 | 0.0 | 0.0 | 1.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Deedrick |
12605 rows × 13 columns
# Merge salaries and genders
salaries_with_gender = salaries.merge(genders[['gender']], on='firstname', how='left')
salaries_with_gender
| Employee Name | Job Title | Base Pay | Overtime Pay | Other Pay | Benefits | Total Pay | Total Pay & Benefits | Year | Notes | Agency | Status | firstname | gender | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Michael Xxxx | Police Officer | 117691.0 | 187290.0 | 13331.00 | 36380.0 | 318312.0 | 354692.0 | 2020 | NaN | San Diego | FT | Michael | M |
| 1 | Gary Xxxx | Police Officer | 117691.0 | 160062.0 | 42946.00 | 31795.0 | 320699.0 | 352494.0 | 2020 | NaN | San Diego | FT | Gary | M |
| 2 | Eric Xxxx | Fire Engineer | 35698.0 | 204462.0 | 69121.00 | 38362.0 | 309281.0 | 347643.0 | 2020 | NaN | San Diego | PT | Eric | M |
| 3 | Gregg Xxxx | Retirement Administrator | 305000.0 | 0.0 | 12814.00 | 24792.0 | 317814.0 | 342606.0 | 2020 | NaN | San Diego | FT | Gregg | M |
| 4 | Joseph Xxxx | Fire Battalion Chief | 94451.0 | 157778.0 | 48151.00 | 42096.0 | 300380.0 | 342476.0 | 2020 | NaN | San Diego | FT | Joseph | M |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 12600 | Elena Xxxx | Asst Eng-Civil | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT | Elena | F |
| 12601 | Gary Xxxx | Police Officer | 0.0 | 2.0 | 0.00 | 0.0 | 2.0 | 2.0 | 2020 | NaN | San Diego | PT | Gary | M |
| 12602 | Sara Xxxx | Asst Planner | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Sara | F |
| 12603 | Kevin Xxxx | Project Ofcr 1 | 0.0 | 1.0 | 0.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Kevin | M |
| 12604 | Deedrick Xxxx | Utility Worker 2 | 0.0 | 0.0 | 1.00 | 0.0 | 1.0 | 1.0 | 2020 | NaN | San Diego | PT | Deedrick | M |
12605 rows × 14 columns
This was our original question. Let's find out!
pd.concat([
salaries_with_gender.groupby('gender')['Total Pay'].describe().T,
salaries_with_gender['Total Pay'].describe().rename('All')
], axis=1)
| F | M | All | |
|---|---|---|---|
| count | 4075.000000 | 8043.000000 | 12605.000000 |
| mean | 63865.752883 | 81297.593808 | 75181.321618 |
| std | 43497.853002 | 51567.740425 | 49634.174460 |
| min | 1.000000 | 0.000000 | 0.000000 |
| 25% | 33084.000000 | 44900.000000 | 41177.000000 |
| 50% | 59975.000000 | 77579.000000 | 71354.000000 |
| 75% | 89854.000000 | 117374.500000 | 106903.000000 |
| max | 295904.000000 | 320699.000000 | 320699.000000 |
n_female = np.count_nonzero(salaries_with_gender['gender'] == 'F')
n_female
4075
Strategy:
salaries_with_gender and compute their median salary.# Observed statistic
female_median = salaries_with_gender.loc[salaries_with_gender['gender'] == 'F']['Total Pay'].median()
# Simulate 1000 samples of size n_female from the population
medians = np.array([])
for _ in np.arange(1000):
median = salaries_with_gender.sample(n_female)['Total Pay'].median()
medians = np.append(medians, median)
medians[:10]
array([72263., 69699., 70880., 70554., 71104., 72511., 70781., 70781.,
72096., 70755.])
title='Median salary of randomly chosen groups from population'
pd.Series(medians).plot(kind='hist', density=True, ec='w', title=title);
plt.axvline(x=female_median, color='red')
plt.legend(['Observed Median Salary of Female Employees', 'Median Salaries of Random Groups']);

pandas!