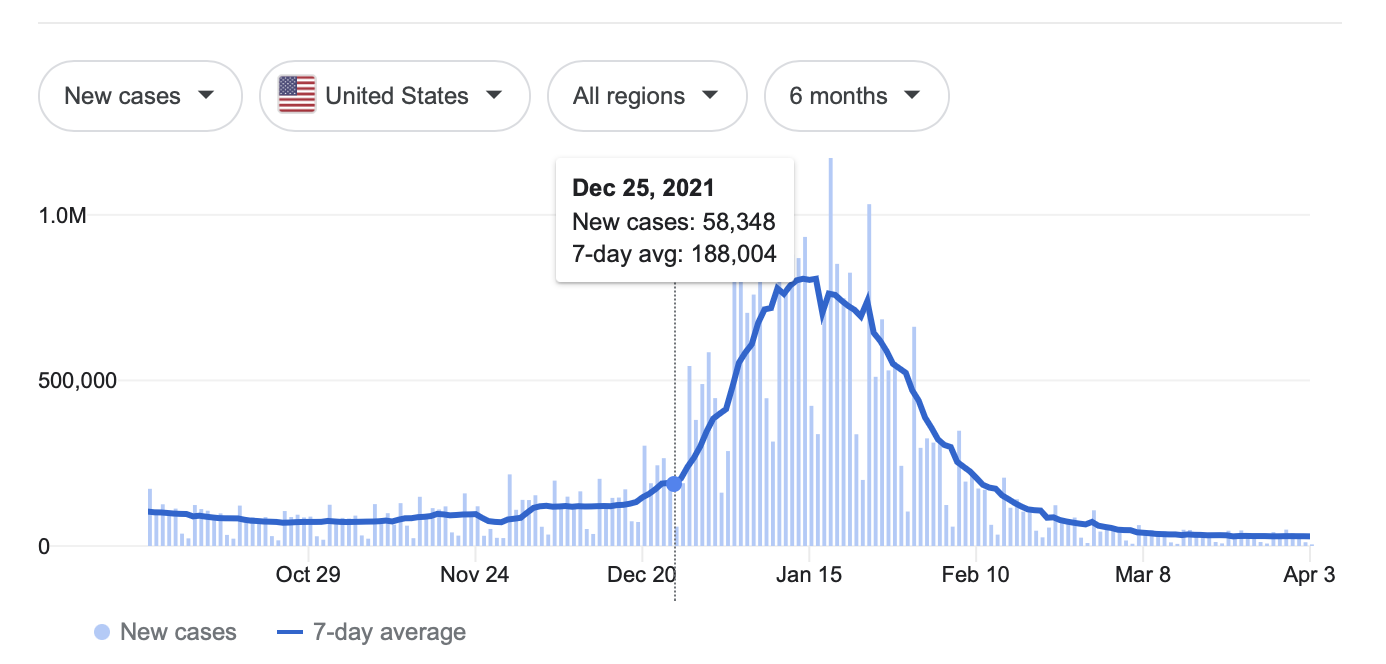
Why do you think so few cases were reported on Christmas Day – is it because COVID was less prevalent on Christmas Day as compared to the days before and after, or is it likely for some other reason? 🎅
import pandas as pd
import numpy as np
import os
elections_fp = os.path.join('data', 'elections.csv')
elections = pd.read_csv(elections_fp)
elections.head(10)
| Candidate | Party | % | Year | Result | |
|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | win |
| 1 | Carter | Democratic | 41.0 | 1980 | loss |
| 2 | Anderson | Independent | 6.6 | 1980 | loss |
| 3 | Reagan | Republican | 58.8 | 1984 | win |
| 4 | Mondale | Democratic | 37.6 | 1984 | loss |
| 5 | Bush | Republican | 53.4 | 1988 | win |
| 6 | Dukakis | Democratic | 45.6 | 1988 | loss |
| 7 | Clinton | Democratic | 43.0 | 1992 | win |
| 8 | Bush | Republican | 37.4 | 1992 | loss |
| 9 | Perot | Independent | 18.9 | 1992 | loss |
assign method.append method.assign and append return a copy of the DataFrame, which is a great feature!As an aside, you should try your best to write chained pandas code, as follows:
(
elections
.assign(proportion_of_vote=(elections['%'] / 100))
.head()
)
| Candidate | Party | % | Year | Result | proportion_of_vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | win | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980 | loss | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980 | loss | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984 | win | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984 | loss | 0.376 |
You can chain together several steps at a time:
(
elections
.assign(proportion_of_vote=(elections['%'] / 100))
.assign(Result=elections['Result'].str.upper())
.head()
)
| Candidate | Party | % | Year | Result | proportion_of_vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | WIN | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980 | LOSS | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980 | LOSS | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984 | WIN | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984 | LOSS | 0.376 |
You can also use assign when the desired column name has spaces, by using keyword arguments.
(
elections
.assign(**{'Proportion of Vote': elections['%'] / 100})
.head()
)
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | win | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980 | loss | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980 | loss | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984 | win | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984 | loss | 0.376 |
loc or [].assign, this modifies the underlying DataFrame rather than a copy of it.# By default, .copy() returns a deep copy of the object it is called on,
# meaning that if you change the copy the original remains unmodified.
mod_elec = elections.copy()
mod_elec.head()
| Candidate | Party | % | Year | Result | |
|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | win |
| 1 | Carter | Democratic | 41.0 | 1980 | loss |
| 2 | Anderson | Independent | 6.6 | 1980 | loss |
| 3 | Reagan | Republican | 58.8 | 1984 | win |
| 4 | Mondale | Democratic | 37.6 | 1984 | loss |
mod_elec['Proportion of Vote'] = mod_elec['%'] / 100
mod_elec.head()
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | win | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980 | loss | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980 | loss | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984 | win | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984 | loss | 0.376 |
mod_elec['Result'] = mod_elec['Result'].str.upper()
mod_elec.head()
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980 | WIN | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980 | LOSS | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980 | LOSS | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984 | WIN | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984 | LOSS | 0.376 |
# 🤔
mod_elec.loc[-1, :] = ['Carter', 'Democratic', 50.1, 1976, 'WIN', 0.501]
mod_elec.loc[-2, :] = ['Ford', 'Republican', 48.0, 1976, 'LOSS', 0.48]
mod_elec
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| 0 | Reagan | Republican | 50.7 | 1980.0 | WIN | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980.0 | LOSS | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980.0 | LOSS | 0.066 |
| 3 | Reagan | Republican | 58.8 | 1984.0 | WIN | 0.588 |
| 4 | Mondale | Democratic | 37.6 | 1984.0 | LOSS | 0.376 |
| 5 | Bush | Republican | 53.4 | 1988.0 | WIN | 0.534 |
| 6 | Dukakis | Democratic | 45.6 | 1988.0 | LOSS | 0.456 |
| 7 | Clinton | Democratic | 43.0 | 1992.0 | WIN | 0.430 |
| 8 | Bush | Republican | 37.4 | 1992.0 | LOSS | 0.374 |
| 9 | Perot | Independent | 18.9 | 1992.0 | LOSS | 0.189 |
| 10 | Clinton | Democratic | 49.2 | 1996.0 | WIN | 0.492 |
| 11 | Dole | Republican | 40.7 | 1996.0 | LOSS | 0.407 |
| 12 | Perot | Independent | 8.4 | 1996.0 | LOSS | 0.084 |
| 13 | Gore | Democratic | 48.4 | 2000.0 | LOSS | 0.484 |
| 14 | Bush | Republican | 47.9 | 2000.0 | WIN | 0.479 |
| 15 | Kerry | Democratic | 48.3 | 2004.0 | LOSS | 0.483 |
| 16 | Bush | Republican | 50.7 | 2004.0 | WIN | 0.507 |
| 17 | Obama | Democratic | 52.9 | 2008.0 | WIN | 0.529 |
| 18 | McCain | Republican | 45.7 | 2008.0 | LOSS | 0.457 |
| 19 | Obama | Democratic | 51.1 | 2012.0 | WIN | 0.511 |
| 20 | Romney | Republican | 47.2 | 2012.0 | LOSS | 0.472 |
| 21 | Clinton | Democratic | 48.2 | 2016.0 | LOSS | 0.482 |
| 22 | Trump | Republican | 46.1 | 2016.0 | WIN | 0.461 |
| 23 | Biden | Democratic | 51.3 | 2020.0 | WIN | 0.513 |
| 24 | Trump | Republican | 46.9 | 2020.0 | LOSS | 0.469 |
| -1 | Carter | Democratic | 50.1 | 1976.0 | WIN | 0.501 |
| -2 | Ford | Republican | 48.0 | 1976.0 | LOSS | 0.480 |
mod_elec = mod_elec.sort_index()
mod_elec.head()
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| -2 | Ford | Republican | 48.0 | 1976.0 | LOSS | 0.480 |
| -1 | Carter | Democratic | 50.1 | 1976.0 | WIN | 0.501 |
| 0 | Reagan | Republican | 50.7 | 1980.0 | WIN | 0.507 |
| 1 | Carter | Democratic | 41.0 | 1980.0 | LOSS | 0.410 |
| 2 | Anderson | Independent | 6.6 | 1980.0 | LOSS | 0.066 |
# df.reset_index(drop=True) drops the current index
# of the DataFrame and replaces it with an index of increasing integers
mod_elec.reset_index(drop=True)
| Candidate | Party | % | Year | Result | Proportion of Vote | |
|---|---|---|---|---|---|---|
| 0 | Ford | Republican | 48.0 | 1976.0 | LOSS | 0.480 |
| 1 | Carter | Democratic | 50.1 | 1976.0 | WIN | 0.501 |
| 2 | Reagan | Republican | 50.7 | 1980.0 | WIN | 0.507 |
| 3 | Carter | Democratic | 41.0 | 1980.0 | LOSS | 0.410 |
| 4 | Anderson | Independent | 6.6 | 1980.0 | LOSS | 0.066 |
| 5 | Reagan | Republican | 58.8 | 1984.0 | WIN | 0.588 |
| 6 | Mondale | Democratic | 37.6 | 1984.0 | LOSS | 0.376 |
| 7 | Bush | Republican | 53.4 | 1988.0 | WIN | 0.534 |
| 8 | Dukakis | Democratic | 45.6 | 1988.0 | LOSS | 0.456 |
| 9 | Clinton | Democratic | 43.0 | 1992.0 | WIN | 0.430 |
| 10 | Bush | Republican | 37.4 | 1992.0 | LOSS | 0.374 |
| 11 | Perot | Independent | 18.9 | 1992.0 | LOSS | 0.189 |
| 12 | Clinton | Democratic | 49.2 | 1996.0 | WIN | 0.492 |
| 13 | Dole | Republican | 40.7 | 1996.0 | LOSS | 0.407 |
| 14 | Perot | Independent | 8.4 | 1996.0 | LOSS | 0.084 |
| 15 | Gore | Democratic | 48.4 | 2000.0 | LOSS | 0.484 |
| 16 | Bush | Republican | 47.9 | 2000.0 | WIN | 0.479 |
| 17 | Kerry | Democratic | 48.3 | 2004.0 | LOSS | 0.483 |
| 18 | Bush | Republican | 50.7 | 2004.0 | WIN | 0.507 |
| 19 | Obama | Democratic | 52.9 | 2008.0 | WIN | 0.529 |
| 20 | McCain | Republican | 45.7 | 2008.0 | LOSS | 0.457 |
| 21 | Obama | Democratic | 51.1 | 2012.0 | WIN | 0.511 |
| 22 | Romney | Republican | 47.2 | 2012.0 | LOSS | 0.472 |
| 23 | Clinton | Democratic | 48.2 | 2016.0 | LOSS | 0.482 |
| 24 | Trump | Republican | 46.1 | 2016.0 | WIN | 0.461 |
| 25 | Biden | Democratic | 51.3 | 2020.0 | WIN | 0.513 |
| 26 | Trump | Republican | 46.9 | 2020.0 | LOSS | 0.469 |
Suppose our goal is to determine the number of COVID cases in the US yesterday.
Why do you think so few cases were reported on Christmas Day – is it because COVID was less prevalent on Christmas Day as compared to the days before and after, or is it likely for some other reason? 🎅
The bigger picture question we're asking here is, can we trust our data?
Data cleaning is the process of transforming data so that it best represents the underlying data generating process.
In practice, data cleaning is often detective work to understand data provenance.
Data cleaning often addresses:
Let's focus on the latter two.
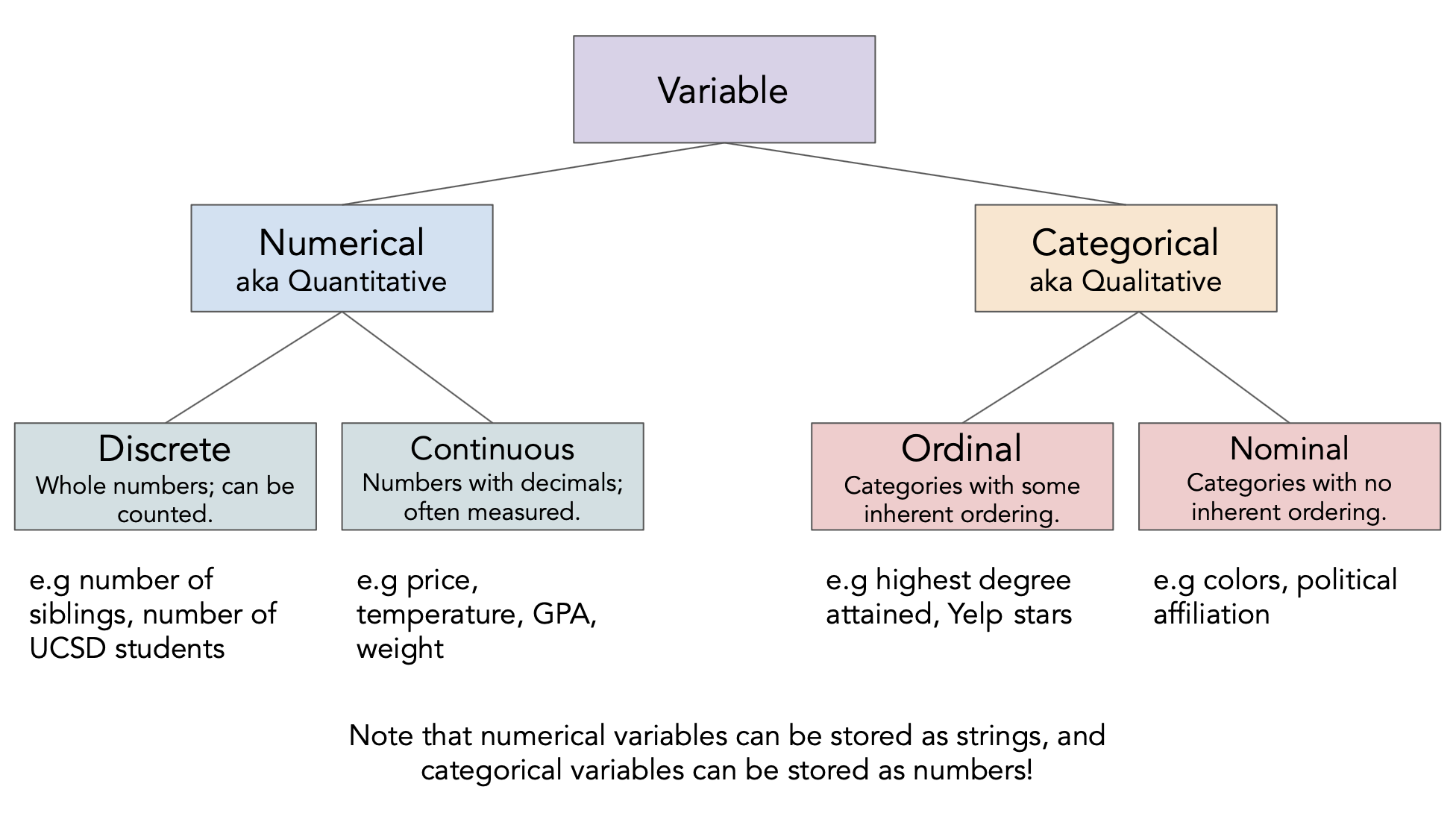
Determine the kind of each of the following variables.
In the next cell, we'll load in an example dataset containing information about past DSC 80 students.
'PID' and 'Student Name': student PID and name.'Month', 'Day', 'Year': date when the student was accepted to UCSD.'2021 tuition' and '2022 tuition': amount paid in tuition in 2021 and 2022, respectively.'Percent Growth': growth between the two aforementioned columns.'Paid': whether or not the student has paid tuition for this quarter yet.'DSC 80 Final Grade': either 'Pass', 'Fail', or a number.What needs to be changed in the DataFrame to compute statistics?
students = pd.read_csv(os.path.join('data', 'students.csv'))
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | $40000.00 | $50000.00 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | $9200.00 | $10120.00 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | $50000.00 | $62500.00 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | $7000.00 | $9800.00 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | $10000.00 | $5000.00 | -50.00% | Y | Pass |
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | $40000.00 | $50000.00 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | $9200.00 | $10120.00 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | $50000.00 | $62500.00 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | $7000.00 | $9800.00 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | $10000.00 | $5000.00 | -50.00% | Y | Pass |
total = students['2021 tuition'] + students['2022 tuition']
total
0 $40000.00$50000.00 1 $9200.00$10120.00 2 $50000.00$62500.00 3 $7000.00$9800.00 4 $10000.00$5000.00 dtype: object
students!¶What data type should each column have?
Use the dtypes attribute (or the info method) to peek at the data types.
students.dtypes
Student ID object Student Name object Month int64 Day int64 Year int64 2021 tuition object 2022 tuition object Percent Growth object Paid object DSC 80 Final Grade object dtype: object
'2021 tuition' and '2022 tuition'¶'2021 tuition' and '2022 tuition' are stored as objects (strings), not numerical values.'$' character causes the entries to be interpreted as strings.str methods to strip the dollar sign.# This won't work. Why?
students['2021 tuition'].astype(float)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_68306/2133079742.py in <module> 1 # This won't work. Why? ----> 2 students['2021 tuition'].astype(float) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/generic.py in astype(self, dtype, copy, errors) 5918 else: 5919 # else, only a single dtype is given -> 5920 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors) 5921 return self._constructor(new_data).__finalize__(self, method="astype") 5922 ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in astype(self, dtype, copy, errors) 417 418 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T: --> 419 return self.apply("astype", dtype=dtype, copy=copy, errors=errors) 420 421 def convert( ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 302 applied = b.apply(f, **kwargs) 303 else: --> 304 applied = getattr(b, f)(**kwargs) 305 except (TypeError, NotImplementedError): 306 if not ignore_failures: ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/blocks.py in astype(self, dtype, copy, errors) 578 values = self.values 579 --> 580 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors) 581 582 new_values = maybe_coerce_values(new_values) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_array_safe(values, dtype, copy, errors) 1290 1291 try: -> 1292 new_values = astype_array(values, dtype, copy=copy) 1293 except (ValueError, TypeError): 1294 # e.g. astype_nansafe can fail on object-dtype of strings ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_array(values, dtype, copy) 1235 1236 else: -> 1237 values = astype_nansafe(values, dtype, copy=copy) 1238 1239 # in pandas we don't store numpy str dtypes, so convert to object ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_nansafe(arr, dtype, copy, skipna) 1179 if copy or is_object_dtype(arr.dtype) or is_object_dtype(dtype): 1180 # Explicit copy, or required since NumPy can't view from / to object. -> 1181 return arr.astype(dtype, copy=True) 1182 1183 return arr.astype(dtype, copy=copy) ValueError: could not convert string to float: '$40000.00'
# That's better!
students['2021 tuition'].str.strip('$').astype(float)
0 40000.0 1 9200.0 2 50000.0 3 7000.0 4 10000.0 Name: 2021 tuition, dtype: float64
We can loop through the columns of students to apply the above procedure. (Looping through columns is fine, just avoid looping through rows.)
for col in students.columns:
if 'tuition' in col:
students[col] = students[col].str.strip('$').astype(float)
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | Y | Pass |
Alternatively, we can do this without a loop by using str.contains to find only the columns that contain tuition information.
cols = students.columns.str.contains('tuition')
students.loc[:, cols] = students.loc[:, cols].astype(float)
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | Y | Pass |
'Paid'¶'Paid' contains the strings 'Y' and 'N'.'Y's and 'N's typically result from manual data entry.'Paid' column should contain Trues and Falses, or 1s and 0s.replace Series method.students['Paid'].replace({'Y': True, 'N': False})
0 False 1 True 2 False 3 True 4 True Name: Paid, dtype: bool
students['Paid'].value_counts()
Y 3 N 2 Name: Paid, dtype: int64
students['Paid'] = students['Paid'] == 'Y'
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | False | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | True | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | False | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | True | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | True | Pass |
'Month', 'Day', and 'Year'¶int64 data type. This could be fine for certain purposes, but ideally they are stored as a single column (e.g. for sorting).'YYYY-MM-DD'.datetime64 objects (later).(
students['Year'].astype(str) + '-' +
students['Month'].astype(str).str.zfill(2) + '-' +
students['Day'].astype(str).str.zfill(2)
)
0 2020-10-12 1 2019-04-15 2 2021-05-14 3 2020-07-10 4 2021-03-03 dtype: object
Note:
zfill string method adds zeroes to the start of a string until it reaches the specified length.'DSC 80 Final Grade'¶'DSC 80 Final Grade's are stored as objects (strings).'Pass', we can't use astype to convert it.pd.to_numeric(s, errors='coerce'), where s is a Series.errors='coerce' can cause uninformed destruction of data.# Won't work!
students['DSC 80 Final Grade'].astype(int)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_68306/1326609327.py in <module> 1 # Won't work! ----> 2 students['DSC 80 Final Grade'].astype(int) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/generic.py in astype(self, dtype, copy, errors) 5918 else: 5919 # else, only a single dtype is given -> 5920 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors) 5921 return self._constructor(new_data).__finalize__(self, method="astype") 5922 ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in astype(self, dtype, copy, errors) 417 418 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T: --> 419 return self.apply("astype", dtype=dtype, copy=copy, errors=errors) 420 421 def convert( ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 302 applied = b.apply(f, **kwargs) 303 else: --> 304 applied = getattr(b, f)(**kwargs) 305 except (TypeError, NotImplementedError): 306 if not ignore_failures: ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/blocks.py in astype(self, dtype, copy, errors) 578 values = self.values 579 --> 580 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors) 581 582 new_values = maybe_coerce_values(new_values) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_array_safe(values, dtype, copy, errors) 1290 1291 try: -> 1292 new_values = astype_array(values, dtype, copy=copy) 1293 except (ValueError, TypeError): 1294 # e.g. astype_nansafe can fail on object-dtype of strings ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_array(values, dtype, copy) 1235 1236 else: -> 1237 values = astype_nansafe(values, dtype, copy=copy) 1238 1239 # in pandas we don't store numpy str dtypes, so convert to object ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/cast.py in astype_nansafe(arr, dtype, copy, skipna) 1152 # work around NumPy brokenness, #1987 1153 if np.issubdtype(dtype.type, np.integer): -> 1154 return lib.astype_intsafe(arr, dtype) 1155 1156 # if we have a datetime/timedelta array of objects ~/opt/anaconda3/lib/python3.9/site-packages/pandas/_libs/lib.pyx in pandas._libs.lib.astype_intsafe() ValueError: invalid literal for int() with base 10: 'Pass'
pd.to_numeric(students['DSC 80 Final Grade'], errors='coerce')
0 89.0 1 90.0 2 97.0 3 54.0 4 NaN Name: DSC 80 Final Grade, dtype: float64
students['DSC 80 Final Grade'] = pd.to_numeric(students['DSC 80 Final Grade'], errors='coerce')
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | False | 89.0 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | True | 90.0 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | False | 97.0 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | True | 54.0 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | True | NaN |
pd.to_numeric?
'Student Name'¶'Last Name, First Name', a common format.apply method.s is a Series, s.apply(func) applies the function func to each entry of s.students['Student Name']
0 John Black 1 Mark White 2 Amy Red 3 Tom Green 4 Rose Pink Name: Student Name, dtype: object
def transpose_name(name):
firstname, lastname = name.split()
return lastname + ', ' + firstname
transpose_name('King Triton')
'Triton, King'
students['Student Name'].apply(transpose_name)
0 Black, John 1 White, Mark 2 Red, Amy 3 Green, Tom 4 Pink, Rose Name: Student Name, dtype: object
str methods are useful – use them!
str attribute of Series.parts = students['Student Name'].str.split()
parts
0 [John, Black] 1 [Mark, White] 2 [Amy, Red] 3 [Tom, Green] 4 [Rose, Pink] Name: Student Name, dtype: object
parts.str[1] + ', ' + parts.str[0]
0 Black, John 1 White, Mark 2 Red, Amy 3 Green, Tom 4 Pink, Rose Name: Student Name, dtype: object
1649043031 looks like a number, but is probably a date.
"USD 1,000,000" looks like a string, but is actually a number and a unit.
92093 looks like a number, but is really a zip code (and isn't equal to 92,093).
Sometimes, False appears in a column of country codes. Why might this be?
🤔
import yaml
player = '''
name: Magnus Carlsen
age: 31
country: NO
'''
yaml.safe_load(player)
{'name': 'Magnus Carlsen', 'age': 31, 'country': False}
In other words, how well does the data represent reality?
Does the data contain unrealistic or "incorrect" values?
The dataset we're working with contains all of the vehicle stops that the San Diego Police Department made in 2016.
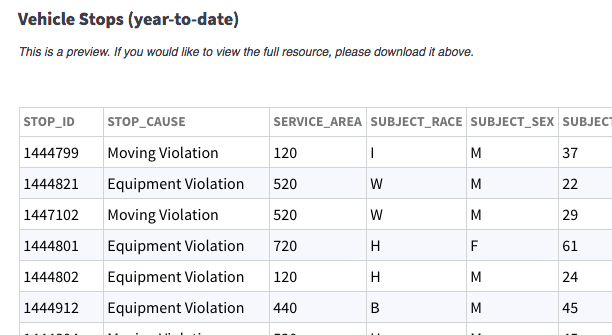
stops = pd.read_csv('data/vehicle_stops_2016_datasd.csv')
stops.head()
| stop_id | stop_cause | service_area | subject_race | subject_sex | subject_age | timestamp | stop_date | stop_time | sd_resident | arrested | searched | obtained_consent | contraband_found | property_seized | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1308198 | Equipment Violation | 530 | W | M | 28 | 2016-01-01 00:06:00 | 2016-01-01 | 0:06 | Y | N | N | N | N | N |
| 1 | 1308172 | Moving Violation | 520 | B | M | 25 | 2016-01-01 00:10:00 | 2016-01-01 | 0:10 | N | N | N | NaN | NaN | NaN |
| 2 | 1308171 | Moving Violation | 110 | H | F | 31 | 2016-01-01 00:14:00 | 2016-01-01 | 0:14 | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 1308170 | Moving Violation | Unknown | W | F | 29 | 2016-01-01 00:16:00 | 2016-01-01 | 0:16 | N | N | N | NaN | NaN | NaN |
| 4 | 1308197 | Moving Violation | 230 | W | M | 52 | 2016-01-01 00:30:00 | 2016-01-01 | 0:30 | N | N | N | NaN | NaN | NaN |
stops.head(1)
| stop_id | stop_cause | service_area | subject_race | subject_sex | subject_age | timestamp | stop_date | stop_time | sd_resident | arrested | searched | obtained_consent | contraband_found | property_seized | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1308198 | Equipment Violation | 530 | W | M | 28 | 2016-01-01 00:06:00 | 2016-01-01 | 0:06 | Y | N | N | N | N | N |
stops.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 103051 entries, 0 to 103050 Data columns (total 15 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 stop_id 103051 non-null int64 1 stop_cause 103044 non-null object 2 service_area 103051 non-null object 3 subject_race 102920 non-null object 4 subject_sex 102865 non-null object 5 subject_age 100284 non-null object 6 timestamp 102879 non-null object 7 stop_date 103051 non-null object 8 stop_time 103051 non-null object 9 sd_resident 83689 non-null object 10 arrested 84400 non-null object 11 searched 83330 non-null object 12 obtained_consent 4791 non-null object 13 contraband_found 4969 non-null object 14 property_seized 4924 non-null object dtypes: int64(1), object(14) memory usage: 11.8+ MB
'subject_age' – some are too old to be true, some are too low to be true.stops['subject_age'].unique()
array(['28', '25', '31', '29', '52', '24', '20', '50', '23', '54', '53',
'35', '38', '18', '48', '68', '45', '63', '49', '42', '27', '19',
'55', '32', '47', '33', '41', '59', '60', '58', '26', '36', '40',
'39', '21', '64', '30', '43', '17', '51', '34', '56', '44', '22',
'69', '46', '16', '57', '37', '65', '72', '67', '66', '70', '62',
'73', '74', '0', '77', nan, '89', '79', '61', '78', '99', '75',
'85', '82', '71', '15', '80', '81', '93', '84', '76', '2', '4',
'86', '91', '83', '88', '98', '87', 'No Age', '9', '100', '14',
'95', '96', '92', '119', '1', '90', '163', '5', '114', '94', '10',
'212', '220', '6', '145', '97', '120'], dtype=object)
ages = pd.to_numeric(stops['subject_age'], errors='coerce')
ages.describe()
count 99648.000000 mean 37.277697 std 14.456934 min 0.000000 25% 25.000000 50% 34.000000 75% 47.000000 max 220.000000 Name: subject_age, dtype: float64
Ages range all over the place, from 0 to 220. Was a 220 year old really pulled over?
stops.loc[ages > 100]
| stop_id | stop_cause | service_area | subject_race | subject_sex | subject_age | timestamp | stop_date | stop_time | sd_resident | arrested | searched | obtained_consent | contraband_found | property_seized | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 25029 | 1333254 | Equipment Violation | 820 | W | F | 119 | 2016-03-19 22:20:00 | 2016-03-19 | 22:20 | N | N | N | NaN | NaN | NaN |
| 34179 | 1375483 | Moving Violation | 510 | W | M | 163 | 2016-04-18 16:35:00 | 2016-04-18 | 16:35 | N | N | N | NaN | NaN | NaN |
| 36968 | 1378369 | Moving Violation | 240 | A | F | 114 | 2016-04-28 11:44:00 | 2016-04-28 | 11:44 | NaN | NaN | NaN | NaN | NaN | NaN |
| 63570 | 1405478 | Moving Violation | 110 | V | M | 212 | 2016-08-04 18:10:00 | 2016-08-04 | 18:10 | Y | N | N | NaN | NaN | NaN |
| 70267 | 1411694 | Moving Violation | 310 | H | F | 220 | 2016-08-30 18:28:00 | 2016-08-30 | 18:28 | Y | N | N | NaN | NaN | NaN |
| 77038 | 1418885 | Moving Violation | 830 | B | M | 145 | 2016-09-22 20:35:00 | 2016-09-22 | 20:35 | Y | N | Y | N | N | NaN |
| 99449 | 1440889 | Equipment Violation | 120 | W | F | 120 | 2016-12-15 19:28:00 | 2016-12-15 | 19:28 | Y | N | N | NaN | NaN | NaN |
ages.loc[(ages >= 0) & (ages < 16)].value_counts()
0.0 218 15.0 27 2.0 6 14.0 5 4.0 4 1.0 2 10.0 2 9.0 1 5.0 1 6.0 1 Name: subject_age, dtype: int64
stops.loc[(ages >= 0) & (ages < 16)]
| stop_id | stop_cause | service_area | subject_race | subject_sex | subject_age | timestamp | stop_date | stop_time | sd_resident | arrested | searched | obtained_consent | contraband_found | property_seized | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 547 | 1308628 | Moving Violation | 120 | W | M | 0 | 2016-01-03 16:20:00 | 2016-01-03 | 16:20 | NaN | NaN | NaN | NaN | NaN | NaN |
| 747 | 1308820 | Moving Violation | Unknown | H | F | 0 | 2016-01-04 22:13:00 | 2016-01-04 | 22:13 | N | N | N | NaN | NaN | NaN |
| 1686 | 1309896 | Moving Violation | 120 | W | M | 15 | 2016-01-08 19:30:00 | 2016-01-08 | 19:30 | N | N | N | NaN | NaN | NaN |
| 1752 | 1309975 | Moving Violation | Unknown | O | M | 0 | 2016-01-08 23:20:00 | 2016-01-08 | 23:20 | N | N | N | NaN | NaN | NaN |
| 2054 | 1310377 | Equipment Violation | 430 | H | F | 0 | 2016-01-10 16:42:00 | 2016-01-10 | 16:42 | Y | N | N | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 100465 | 1442806 | Moving Violation | 810 | O | M | 15 | 2016-12-20 10:45:00 | 2016-12-20 | 10:45 | Y | N | N | NaN | NaN | NaN |
| 101495 | 1443500 | Moving Violation | 320 | W | M | 0 | 2016-12-23 22:30:00 | 2016-12-23 | 22:30 | NaN | NaN | NaN | NaN | NaN | NaN |
| 101784 | 1443745 | Moving Violation | Unknown | O | M | 0 | 2016-12-26 19:30:00 | 2016-12-26 | 19:30 | NaN | NaN | NaN | NaN | NaN | NaN |
| 101790 | 1443747 | Moving Violation | 320 | W | F | 0 | 2016-12-26 20:00:00 | 2016-12-26 | 20:00 | NaN | NaN | NaN | NaN | NaN | NaN |
| 102848 | 1444647 | Moving Violation | 320 | W | M | 0 | 2016-12-31 17:45:00 | 2016-12-31 | 17:45 | NaN | NaN | NaN | NaN | NaN | NaN |
267 rows × 15 columns
'subject_age'¶'No Age' and 0 are likely explicit null values.In the coming weeks, we'll cover more solutions to these problems.