In [5]:
plt.hist([heights['child'], heights_mcar['child'].dropna(), heights_mcar_mfilled['child']])
plt.legend(['full data', 'missing (mcar)', 'imputed']);

import pandas as pd
import numpy as np
import os
import util
import matplotlib.pyplot as plt
plt.style.use('seaborn-white')
plt.rc('figure', dpi=100, figsize=(10, 5))
plt.rc('font', size=12)
heights = pd.read_csv(os.path.join('data', 'heights.csv'))
heights = (
heights
.rename(columns={'childHeight': 'child', 'childNum': 'number'})
.drop('midparentHeight', axis=1)
)
heights.head()
| family | father | mother | children | number | gender | child | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 78.5 | 67.0 | 4 | 1 | male | 73.2 |
| 1 | 1 | 78.5 | 67.0 | 4 | 2 | female | 69.2 |
| 2 | 1 | 78.5 | 67.0 | 4 | 3 | female | 69.0 |
| 3 | 1 | 78.5 | 67.0 | 4 | 4 | female | 69.0 |
| 4 | 2 | 75.5 | 66.5 | 4 | 1 | male | 73.5 |
np.random.seed(42) # So that we get the same results each time (for lecture)
heights_mcar = util.make_mcar(heights, 'child', pct=0.50)
heights_mcar.head()
| family | father | mother | children | number | gender | child | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 78.5 | 67.0 | 4 | 1 | male | 73.2 |
| 1 | 1 | 78.5 | 67.0 | 4 | 2 | female | 69.2 |
| 2 | 1 | 78.5 | 67.0 | 4 | 3 | female | NaN |
| 3 | 1 | 78.5 | 67.0 | 4 | 4 | female | NaN |
| 4 | 2 | 75.5 | 66.5 | 4 | 1 | male | 73.5 |
The 'child' column has missing values.
'child' is MCAR, then fill in each of the missing values using the mean of the observed values.'child' is MAR dependent on a categorical column, then fill in each of the missing values using the mean of the observed values in each category. For instance, if 'child' is MAR dependent on 'gender', we can fill in:'child' heights with the observed mean for female children, and'child' heights with the observed mean for male children.'child' is MAR dependent on a numerical column, then bin the numerical column to make it categorical, then follow the procedure above. See Lab 5, Question 3!heights_mcar_mfilled = heights_mcar.fillna(heights_mcar['child'].mean())
heights_mcar_mfilled['child'].head()
0 73.200000 1 69.200000 2 66.640685 3 66.640685 4 73.500000 Name: child, dtype: float64
plt.hist([heights['child'], heights_mcar['child'].dropna(), heights_mcar_mfilled['child']])
plt.legend(['full data', 'missing (mcar)', 'imputed']);
The 'child' column has missing values.
'child' is MCAR, then fill in each of the missing values with randomly selected observed 'child' heights.'child' values, pick 5 of the not-missing 'child' values.'child' is MAR dependent on a categorical column, sample from the observed values separately for each category.# Figure out the number of missing values
num_null = heights_mcar['child'].isna().sum()
# Sample that number of values from the observed dataset
fill_values = heights_mcar['child'].dropna().sample(num_null, replace=True)
# Find the positions where values in heights_mcar are missing
fill_values.index = heights_mcar.loc[heights_mcar['child'].isna()].index
# Fill in the missing values
heights_mcar_dfilled = heights_mcar.fillna({'child': fill_values.to_dict()}) # fill the vals
plt.hist([heights['child'], heights_mcar['child'], heights_mcar_dfilled['child']], density=True);
plt.legend(['full data','missing (mcar)', 'distr imputed']);

No spikes!
If a value was never observed in the dataset, it will never be used to fill in a missing value.
Solution? Create a histogram (with np.histogram) to bin the data, then sample from the histogram. See Lab 5, Question 4.
Steps:
Create several imputed versions of the data through a probabilistic procedure.
Then, estimate the parameters of interest for each imputed dataset.
Let's try this procedure out on the heights_mcar dataset.
heights_mcar.head()
| family | father | mother | children | number | gender | child | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 78.5 | 67.0 | 4 | 1 | male | 73.2 |
| 1 | 1 | 78.5 | 67.0 | 4 | 2 | female | 69.2 |
| 2 | 1 | 78.5 | 67.0 | 4 | 3 | female | NaN |
| 3 | 1 | 78.5 | 67.0 | 4 | 4 | female | NaN |
| 4 | 2 | 75.5 | 66.5 | 4 | 1 | male | 73.5 |
# This function implements the 3-step process we studied earlier
def create_imputed(col):
num_null = col.isna().sum()
fill_values = col.dropna().sample(num_null, replace=True)
fill_values.index = col.loc[col.isna()].index
return col.fillna(fill_values.to_dict())
Each time we run the following cell, it generates a new imputed version of the 'child' column.
create_imputed(heights_mcar['child']).head()
0 73.2 1 69.2 2 67.7 3 66.0 4 73.5 Name: child, dtype: float64
Let's run the above procedure 100 times.
mult_imp = pd.concat([create_imputed(heights_mcar['child']).rename(k) for k in range(100)], axis=1)
mult_imp.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | ... | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 | 73.2 |
| 1 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | ... | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 | 69.2 |
| 2 | 64.5 | 72.0 | 67.0 | 69.0 | 69.0 | 70.0 | 69.0 | 67.0 | 67.0 | 64.0 | ... | 65.7 | 65.0 | 65.7 | 70.7 | 73.0 | 65.0 | 66.0 | 63.0 | 71.0 | 69.0 |
| 3 | 63.5 | 64.5 | 61.7 | 67.2 | 61.0 | 64.0 | 66.0 | 56.0 | 60.0 | 62.0 | ... | 67.2 | 64.5 | 68.0 | 62.0 | 64.0 | 62.0 | 66.0 | 65.5 | 69.0 | 64.5 |
| 4 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | ... | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 | 73.5 |
5 rows × 100 columns
Let's plot some of the imputed columns above.
# Random sample of 15 imputed columns
mult_imp.sample(15, axis=1).plot(kind='kde', alpha=0.5, legend=False);

Let's look at the distribution of means across the imputed columns.
mult_imp.mean().plot(kind='hist', bins=20, ec='w', density=True);

See the end of Lecture 13 for a detailed summary of all imputation techniques that we've seen so far.
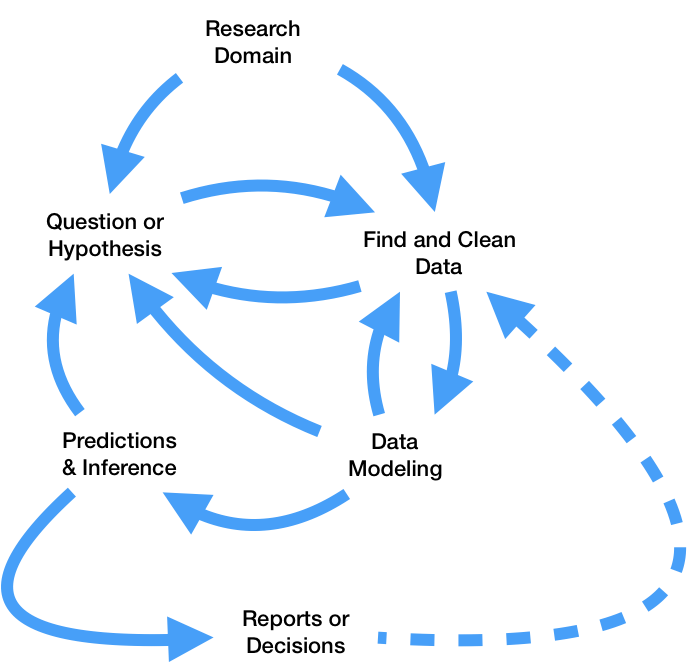
.csv files.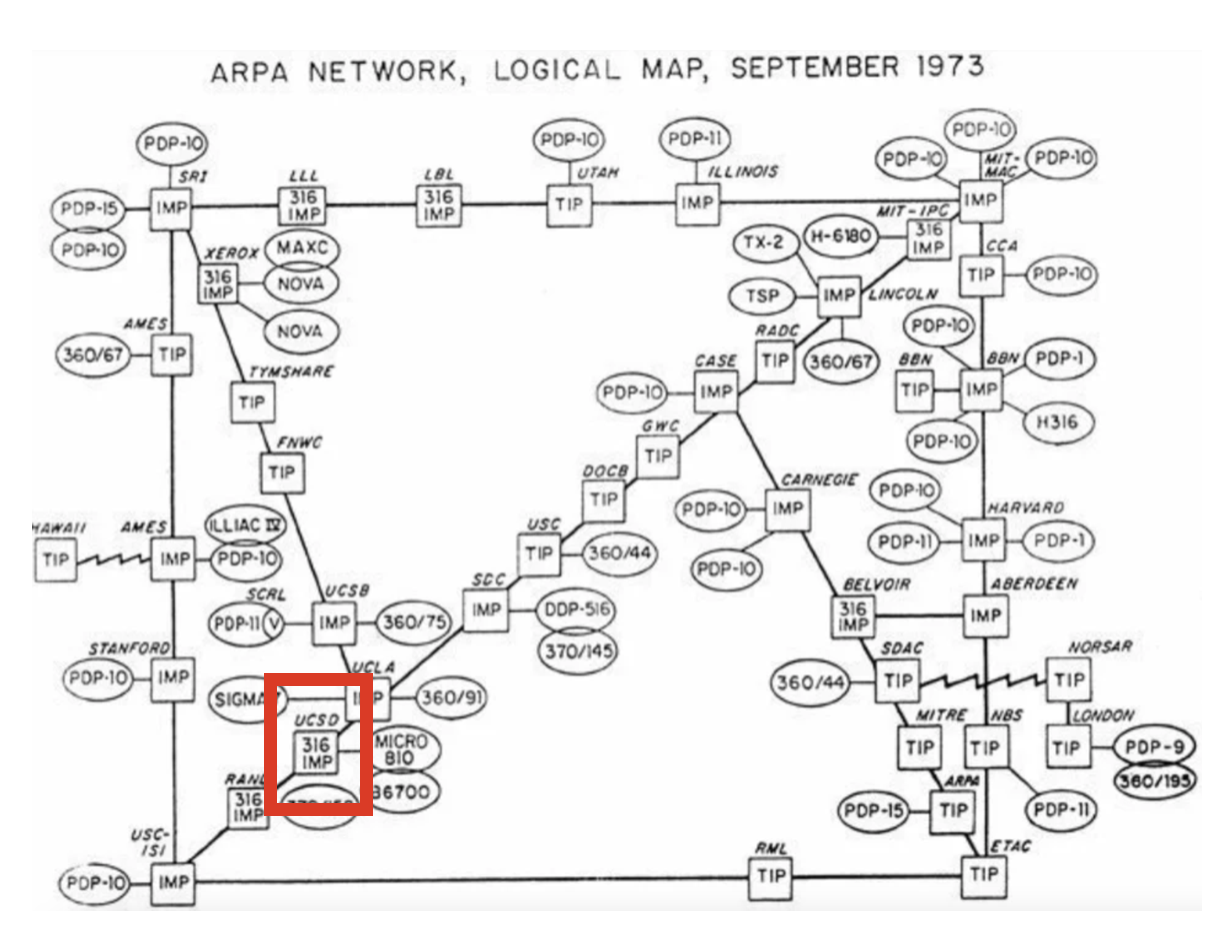
UCSD was a node in ARPANET, the predecessor to the modern internet (source).
HTTP follows the request-response model.
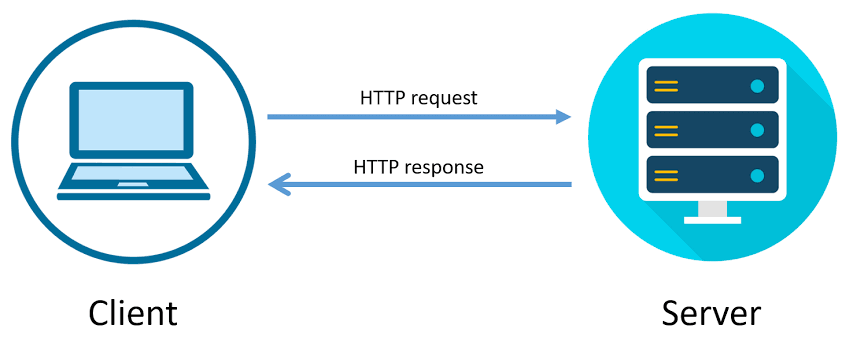
The request methods you will use most often are GET and POST.
GET is used to request data from a specified resource.
POST is used to send data to the server.
See Mozilla's web docs for a detailed list of request methods.
GET request¶Below is an example GET HTTP request made by a browser when accessing datascience.ucsd.edu.
GET / HTTP/1.1
Host: datascience.ucsd.edu
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36
Connection: keep-alive
Accept-Language: en-US,en;q=0.9
GET / HTTP/1.1) is called the "request line", and the lines afterwards are called "header fields". We could also provide a "body" after the header fields.GET response¶The response below was generated by executing the request on the previous slide.
HTTP/1.1 200 OK
Date: Fri, 29 Apr 2022 02:54:41 GMT
Server: Apache
Link: <https://datascience.ucsd.edu/wp-json/>; rel="https://api.w.org/"
Link: <https://datascience.ucsd.edu/wp-json/wp/v2/pages/2427>; rel="alternate"; type="application/json"
Link: <https://datascience.ucsd.edu/>; rel=shortlink
Content-Type: text/html; charset=UTF-8
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<link rel="profile" href="https://gmpg.org/xfn/11">
<style media="all">img.wp-smiley,img.emoji{display:inline !important;border:none
...

Read Inside a viral website, an account of what it's like to run a site that gained 50 million+ views in 5 days.
There are (at least) two ways to make HTTP requests:
curl.requests package.curl¶curl is a command-line tool that sends HTTP requests, like a browser.
curl, sends a HTTP request. GET or POST).GET requests via curl¶curl issues a GET request.! before them.curl -v https://httpbin.org/html
# (`-v` is short for verbose)
!curl -v https://httpbin.org/html
GET request¶? begins a query. For instance,https://www.google.com/search?q=ucsd+dsc+80+hard&client=safariPOST requests via curl¶curl, -d is short for POST.curl POST request that sends 'King Triton' as the parameter 'name'.curl -d 'name=King Triton' https://httpbin.org/post
!curl -d 'name=King Triton' https://httpbin.org/post
!curl -d 'name=King Triton' https://youtube.com
requests¶requests is a Python package that allows you to use Python to interact with the internet! urllib), but requests is arguably the easiest to use.import requests
GET requests via requests¶To access the source code of the UCSD home page, all we need to run is the following:
text = requests.get('https://ucsd.edu').text
url = 'https://ucsd.edu'
resp = requests.get(url)
resp is now a Response object.
resp
<Response [200]>
The text attribute of resp is a string that containing the entire response.
type(resp.text)
str
len(resp.text)
43692
print(resp.text[:1000])
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8"/>
<meta content="IE=edge" http-equiv="X-UA-Compatible"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<title>University of California San Diego</title>
<meta content="University of California, San Diego" name="ORGANIZATION"/>
<meta content="index,follow,noarchive" name="robots"/>
<meta content="UCSD" name="SITE"/>
<meta content="University of California San Diego" name="PAGETITLE"/>
<meta content="The University California San Diego is one of the world's leading public research universities, located in beautiful La Jolla, California" name="DESCRIPTION"/>
<link href="favicon.ico" rel="icon"/>
<!-- Site-specific CSS files -->
<link href="https://www.ucsd.edu/_resources/css/vendor/brix_sans.css" rel="stylesheet" type="text/css"/>
<!-- CSS complied from style overrides -->
<link href="https://www.ucsd.edu/_resources/css/s
The url attribute contains the URL that we accessed.
resp.request.url
'https://ucsd.edu/'
POST requests via requests¶post_response = requests.post('https://httpbin.org/post',
data={'name': 'King Triton'})
post_response
<Response [200]>
print(post_response.text)
{
"args": {},
"data": "",
"files": {},
"form": {
"name": "King Triton"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Content-Length": "16",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.26.0",
"X-Amzn-Trace-Id": "Root=1-626b9412-7d96f8fc5ad980b61f34ae79"
},
"json": null,
"origin": "70.95.172.151",
"url": "https://httpbin.org/post"
}
200, which means there were no issues. 404: page not found; 500: internal server error.404.r = requests.get('https://httpstat.us/503')
print(r.status_code)
503
r.text
'503 Service Unavailable'
ok attribute, which returns a bool.time.sleep).status_codes = [200, 201, 403, 404, 503]
for code in status_codes:
r = requests.get(f'https://httpstat.us/{code}')
print(f'{code} ok: {r.ok}')
200 ok: True 201 ok: True 403 ok: False 404 ok: False 503 ok: False
raise_for_status request method raises an exception when the status code is not-ok.requests.get('https://httpstat.us/400').raise_for_status()
--------------------------------------------------------------------------- HTTPError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_8477/2094305732.py in <module> ----> 1 requests.get('https://httpstat.us/400').raise_for_status() ~/opt/anaconda3/lib/python3.9/site-packages/requests/models.py in raise_for_status(self) 951 952 if http_error_msg: --> 953 raise HTTPError(http_error_msg, response=self) 954 955 def close(self): HTTPError: 400 Client Error: Bad Request for url: https://httpstat.us/400
The internet currently relies on two key data formats – HTML and JSON.
GET request is usually either JSON (when using an API) or HTML (when accessing a webpage).POST request is usually JSON.
true and false.[].null.See json-schema.org for more details.
import json
f = open(os.path.join('data', 'family.json'), 'r')
family_tree = json.load(f)
family_tree
{'name': 'Grandma',
'age': 94,
'children': [{'name': 'Dad',
'age': 60,
'children': [{'name': 'Me', 'age': 23}, {'name': 'Brother', 'age': 21}]},
{'name': 'My Aunt',
'children': [{'name': 'Cousin 1', 'age': 34},
{'name': 'Cousin 2',
'age': 36,
'children': [{'name': 'Cousin 2 Jr.', 'age': 2}]}]}]}
family_tree['children'][0]['children'][0]['age']
23
eval¶eval, which stands for "evaluate", is a function built into Python.x = 4
eval('x + 5')
9
eval can do the same thing that json.load does...f = open(os.path.join('data', 'family.json'), 'r')
eval(f.read())
{'name': 'Grandma',
'age': 94,
'children': [{'name': 'Dad',
'age': 60,
'children': [{'name': 'Me', 'age': 23}, {'name': 'Brother', 'age': 21}]},
{'name': 'My Aunt',
'children': [{'name': 'Cousin 1', 'age': 34},
{'name': 'Cousin 2',
'age': 36,
'children': [{'name': 'Cousin 2 Jr.', 'age': 2}]}]}]}
eval. The next slide demonstrates why.eval gone wrong¶eval on a string representation of a JSON object:f_other = open(os.path.join('data', 'evil_family.json'))
eval(f_other.read())
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_8477/3392341705.py in <module> 1 f_other = open(os.path.join('data', 'evil_family.json')) ----> 2 eval(f_other.read()) <string> in <module> ~/Desktop/80/private/lectures/sp22/lec14/util.py in err() 132 # For JSON evaluation example 133 def err(): --> 134 raise ValueError('i just deleted all your files lol 😂') ValueError: i just deleted all your files lol 😂
evil_family.json, which could have been downloaded from the internet, contained malicious code, we now lost all of our files.eval evaluates all parts of the input string as if it were Python code. You never need to do this – instead, use the json library.json.load loads a JSON file from a file.json.loads loads a JSON file from a string.f_other = open(os.path.join('data', 'evil_family.json'))
s = f_other.read()
s
'{\n "name": "Grandma",\n "age": 94,\n "children": [\n {\n "name": util.err(),\n "age": 60,\n "children": [{"name": "Me", "age": 23}, \n {"name": "Brother", "age": 21}]\n },\n {\n "name": "My Aunt",\n "children": [{"name": "Cousin 1", "age": 34}, \n {"name": "Cousin 2", "age": 36, "children": \n [{"name": "Cousin 2 Jr.", "age": 2}]\n }\n ]\n }\n ]\n}'
json.loads(s)
--------------------------------------------------------------------------- JSONDecodeError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_8477/1938830664.py in <module> ----> 1 json.loads(s) ~/opt/anaconda3/lib/python3.9/json/__init__.py in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw) 344 parse_int is None and parse_float is None and 345 parse_constant is None and object_pairs_hook is None and not kw): --> 346 return _default_decoder.decode(s) 347 if cls is None: 348 cls = JSONDecoder ~/opt/anaconda3/lib/python3.9/json/decoder.py in decode(self, s, _w) 335 336 """ --> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end()) 338 end = _w(s, end).end() 339 if end != len(s): ~/opt/anaconda3/lib/python3.9/json/decoder.py in raw_decode(self, s, idx) 353 obj, end = self.scan_once(s, idx) 354 except StopIteration as err: --> 355 raise JSONDecodeError("Expecting value", s, err.value) from None 356 return obj, end JSONDecodeError: Expecting value: line 6 column 17 (char 84)
util.err() is not a string in JSON (there are no quotes around it), json.loads is not able to parse it as a JSON object.eval on "raw" data that you didn't create!GET HTTP requests to ask for information and POST HTTP requests to send information.curl in the command-line or the requests Python package to make HTTP requests.json package to parse them, not eval.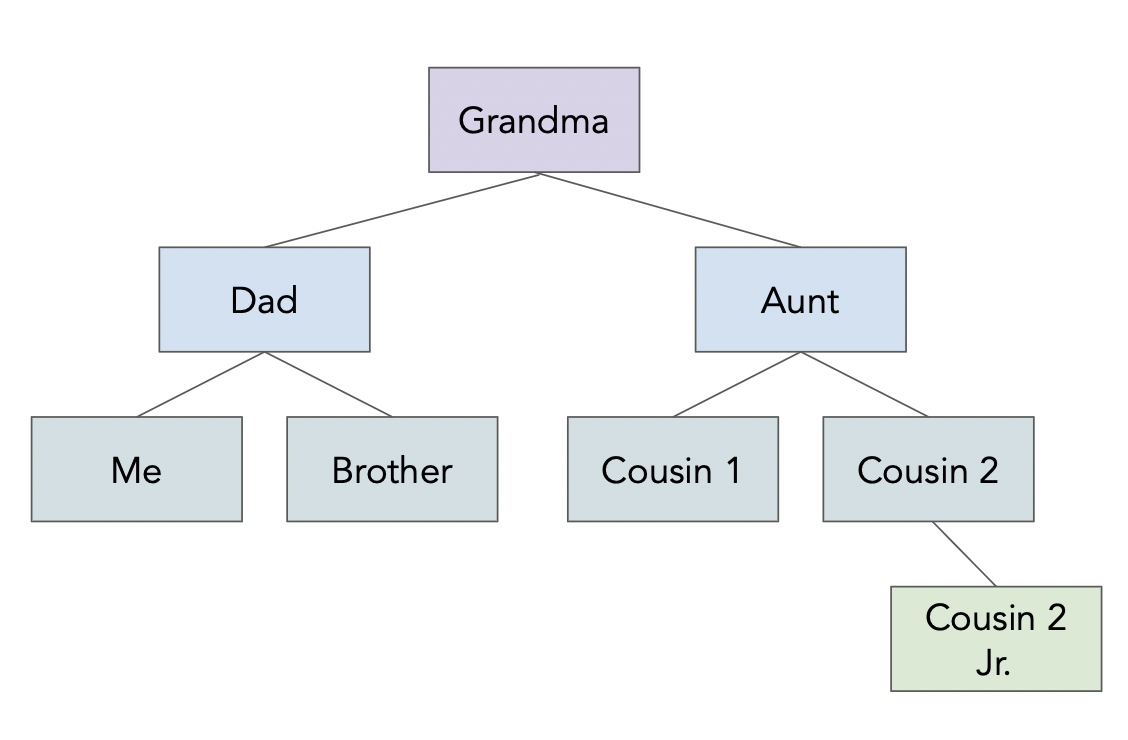
{kind=link}