Heading here
My First paragraph
My second paragraph
import pandas as pd
import numpy as np
import requests
from IPython.display import HTML, Image
requests package to exchange data via HTTP.GET requests are used to request data from a server.POST requests are used to send data to a server. A URL, or uniform resource locator, describes the location of a website or resource.
An API endpoint is a URL of the data source that the user wants to make requests to.
For example, on the Reddit API:
/comments endpoint retrieves information about comments./hot endpoint retrieves data about posts labeled "hot" right now. GET/POST requests to a specially maintained URL.First, let's make a GET request for 'squirtle'.
r = requests.get('https://pokeapi.co/api/v2/pokemon/squirtle')
r
<Response [200]>
Remember, the 200 status code is good! Let's take a look at the content:
r.content[:1000]
b'{"abilities":[{"ability":{"name":"torrent","url":"https://pokeapi.co/api/v2/ability/67/"},"is_hidden":false,"slot":1},{"ability":{"name":"rain-dish","url":"https://pokeapi.co/api/v2/ability/44/"},"is_hidden":true,"slot":3}],"base_experience":63,"forms":[{"name":"squirtle","url":"https://pokeapi.co/api/v2/pokemon-form/7/"}],"game_indices":[{"game_index":177,"version":{"name":"red","url":"https://pokeapi.co/api/v2/version/1/"}},{"game_index":177,"version":{"name":"blue","url":"https://pokeapi.co/api/v2/version/2/"}},{"game_index":177,"version":{"name":"yellow","url":"https://pokeapi.co/api/v2/version/3/"}},{"game_index":7,"version":{"name":"gold","url":"https://pokeapi.co/api/v2/version/4/"}},{"game_index":7,"version":{"name":"silver","url":"https://pokeapi.co/api/v2/version/5/"}},{"game_index":7,"version":{"name":"crystal","url":"https://pokeapi.co/api/v2/version/6/"}},{"game_index":7,"version":{"name":"ruby","url":"https://pokeapi.co/api/v2/version/7/"}},{"game_index":7,"version":{"nam'
Looks like JSON. We can extract the JSON from this request with the json method (or by passing r.text to json.loads).
r.json()
Let's try a GET request for 'billy'.
r = requests.get('https://pokeapi.co/api/v2/pokemon/billy')
r
<Response [404]>
Uh oh...
Let's make a GET request to the HDSI Faculty page and see what the resulting HTML looks like.
url = 'https://datascience.ucsd.edu/about/faculty/faculty/'
r = requests.get(url)
r
<Response [200]>
urlText = r.text
len(urlText)
1287143
print(urlText[:1000])
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<link rel="profile" href="https://gmpg.org/xfn/11">
<style media="all">img.wp-smiley,img.emoji{display:inline !important;border:none !important;box-shadow:none !important;height:1em !important;width:1em !important;margin:0 .07em !important;vertical-align:-.1em !important;background:0 0 !important;padding:0 !important}
.tribe-common{-webkit-font-smoothing:antialiased;-moz-osx-font-smoothing:grayscale;font-smoothing:antialiased}.tribe-common *{box-sizing:border-box}.tribe-common article,.tribe-common aside,.tribe-common details,.tribe-common figcaption,.tribe-common figure,.tribe-common footer,.tribe-common header,.tribe-common main,.tribe-common menu,.tribe-common nav,.tribe-common section,.tribe-common summary{display:block}.tribe-common svg:not(:root){overflow:hidden}.tribe-common audio,.tribe-common canvas,.tribe-common progress,.tribe-common video{display:inline-block}.tribe-common audio:not([controls]){display:non
Wow, that is gross looking! 😰
robots.txt file.robots.txt file in their root directory, which contains a policy that allows or disallows automatic access to their site. If you make too many requests:
!cat data/lec15_ex1.html
<html> <head> <title>Page title</title> </head> <body> <h1>This is a heading</h1> <p>This is a paragraph.</p> <p>This is another paragraph.</p> </body> </html>
HTML document: The totality of markup that makes up a webpage.
Document Object Model (DOM): The internal representation of a HTML document as a hierarchical tree structure.
HTML element: An object in the DOM, such as a paragraph, header, or title.
<p> and </p>.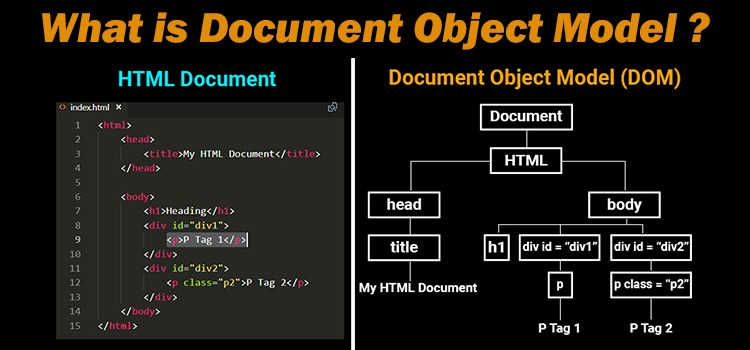
| Element | Description |
|---|---|
<html> |
the document |
<head> |
the header |
<body> |
the body |
<div> |
a logical division of the document |
<span> |
an in-line logical division |
<p> |
a paragraph |
<a> |
an anchor (hyper-link) |
<h1>, <h2>, ... |
header(s) |
<img> |
an image |
There are many, many more. See this article for examples.
Tags can have attributes, which further specify how to display information on a webpage.
For instance, <img> tags have src and alt attributes (among others):
<img src="billy-selfie.png" alt="A photograph of Billy." width=500>
Hyperlinks have href attributes:
Click <a href="https://dsc80.com/project3">this link</a> to access Project 3.
What do you think this webpage looks like?
!cat data/lec15_ex2.html
<html>
<head>
<title>Project 3 - DSC 80, Spring 2022</title>
</head>
<body>
<h1>Project Overview</h1>
<img src="../imgs/mountain_lecture.png" width="200" alt="A sunset in the mountains.">
<p>Start Project 3 by cloning our <a href="https://github.com/dsc-courses/dsc80-2022-sp/">public GitHub repo</a>.
Note that there is <b>no checkpoint</b> for Project 3!
</p>
<center><h3>Make sure to submit your work as a PDF, not a notebook.</h3></center>
</body>
</html>
<div> tag¶<div style="background-color:lightblue">
<h3>This is a heading</h3>
<p>This is a paragraph.</p>
</div>
The <div> tag defines a division or a "section" of an HTML document.
<div> as a "cell" in a Jupyter Notebook.The <div> element is often used as a container for other HTML elements to style them with CSS or to perform operations involving them using JavaScript.
<div> elements often have attributes, which are important when scraping!
!cat data/lec15_ex1.html
<html> <head> <title>Page title</title> </head> <body> <h1>This is a heading</h1> <p>This is a paragraph.</p> <p>This is another paragraph.</p> </body> </html>
Under the document object model (DOM), HTML documents are trees. In DOM trees, child nodes are ordered.
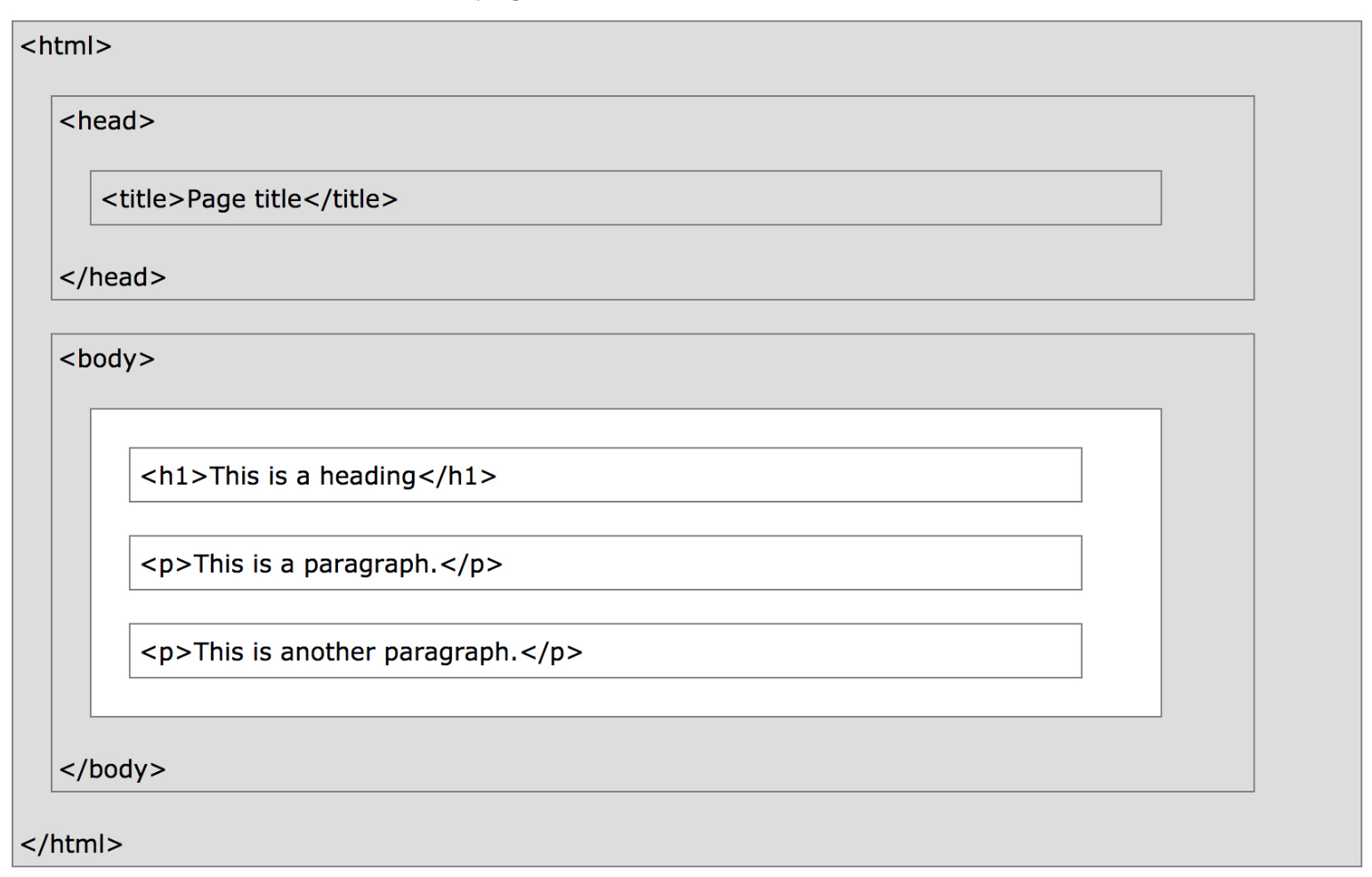
What does the DOM tree look like for this document?
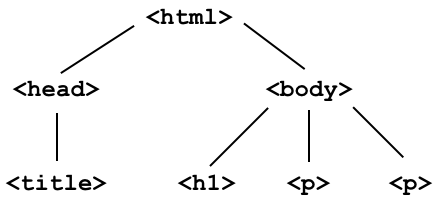
Consider the following webpage.
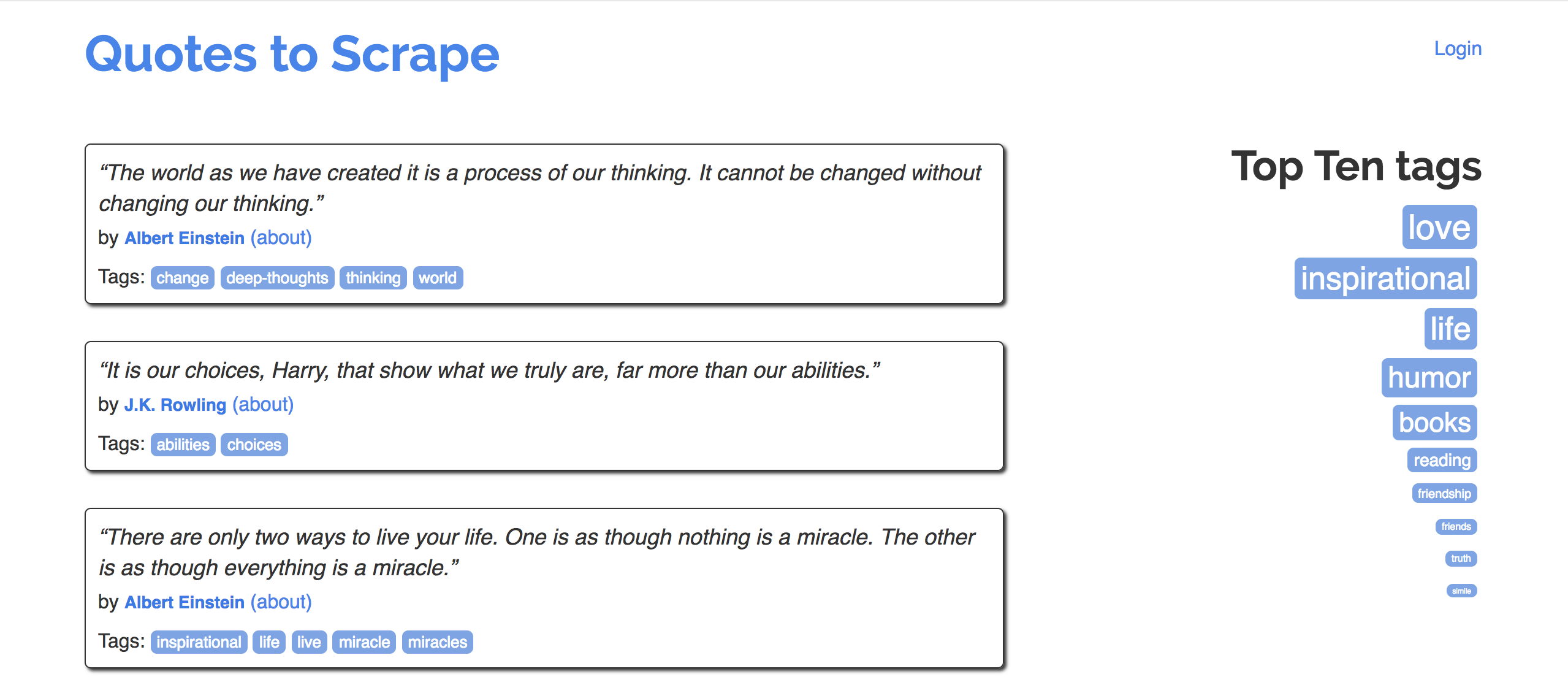
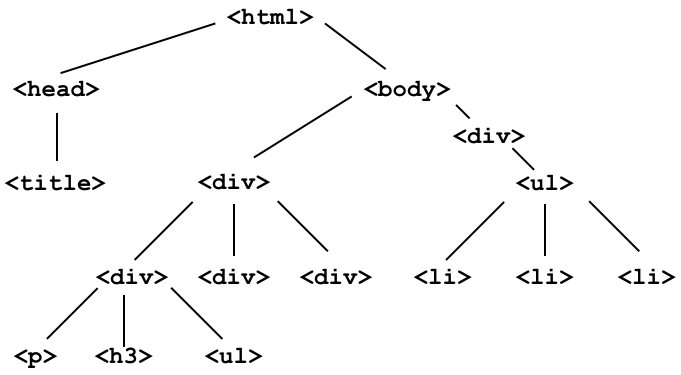
To start, let's instantiate a BeautifulSoup object, using the source code for an HTML page with the DOM tree shown below:
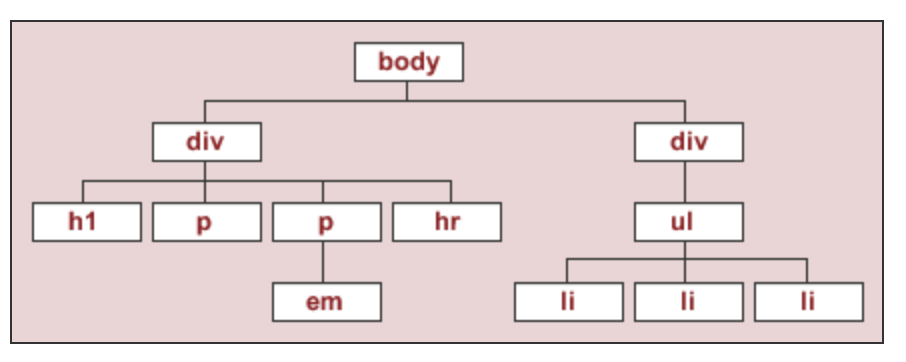
The string html_string contains an HTML "document".
html_string = '''
<html>
<body>
<div id="content">
<h1>Heading here</h1>
<p>My First paragraph</p>
<p>My <em>second</em> paragraph</p>
<hr>
</div>
<div id="nav">
<ul>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</div>
</body>
</html>
'''.strip()
Using the HTML function in the IPython.display module, we can render an HTML document from within our Jupyter Notebook:
HTML(html_string)
My First paragraph
My second paragraph
BeautifulSoup objects¶bs4.BeautifulSoup takes in a string or file-like object representing HTML (markup) and returns a parsed document.
import bs4
bs4.BeautifulSoup?
Normally, we pass the result of a GET request to bs4.BeautifulSoup, but here we will pass our hand-crafted html_string.
soup = bs4.BeautifulSoup(html_string)
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
type(soup)
bs4.BeautifulSoup
BeautifulSoup objects have several useful attributes, e.g. text:
print(soup.text)
Heading here My First paragraph My second paragraph item 1 item 2 item 3
BeautifulSoup object represents a node in the tree.BeautifulSoup object has 0 or more child nodes.children attribute.soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
soup.children
<list_iterator at 0x7f9372b7d610>
nums = [1, 2, 3, 4]
double = map(lambda x: x ** 2, nums)
double
<map at 0x7f93507e66d0>
next(double)
1
list(double)
[4, 9, 16]
The children attribute returns an iterator so that it doesn't have to load the entire DOM tree in memory.
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
soup.children
<list_iterator at 0x7f9372b7d7c0>
len(list(soup.children))
1
root = next(soup.children)
root
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
list(root.children)
['\n', <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body>, '\n']
list(list(root.children)[1].children)
['\n', <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>, '\n', <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>, '\n']
list(list(list(root.children)[1].children)[3].children)
['\n', <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul>, '\n']
descendants¶While we could use the children attribute to navigate to any node in a BeautifulSoup tree, there are easier ways of navigating the tree.
The descendants attribute traverses a BeautifulSoup tree using depth-first traversal.
for child in soup.descendants:
# print(child) # What would happen if we ran this instead?
if isinstance(child, str):
continue
print(child.name)
html body div h1 p p em hr div ul li li li
Practically speaking, you will not use the children or descendants attributes directly very often. Instead, you will use the following methods:
soup.find(tag), which finds the first instance of a tag (the first one on the page, i.e. the first one that DFS sees).soup.find(name=None, attrs={}, recursive=True, text=None, **kwargs).soup.find_all(tag) will find all instances of a tag.soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
div = soup.find('div')
div
<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>
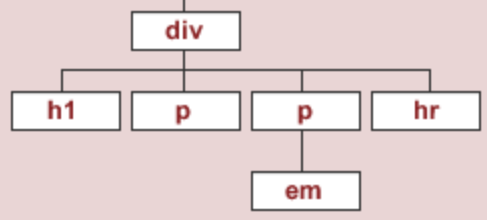
Let's try and find the <div> element that has an id attribute equal to 'nav'.
soup.find('div', attrs={'id': 'nav'})
<div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>
find will return the first occurrence of a tag, regardless of what depth it is in the tree.
soup.find('ul')
<ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul>
soup.find('li')
<li>item 1</li>
find_all¶find_all returns a list of all matches.
soup.find_all('div')
[<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>, <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>]
soup.find_all('li')
[<li>item 1</li>, <li>item 2</li>, <li>item 3</li>]
[x.text for x in soup.find_all('li')]
['item 1', 'item 2', 'item 3']
text is a node attribute.
text attribute of a tag element gets the text between the opening and closing tags.attrs attribute lists all attributes of a tag.get(key) method gets the value of a tag attribute.soup.find('p')
<p>My First paragraph</p>
soup.find('p').text
'My First paragraph'
soup.find('div')
<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>
soup.find('div').attrs
{'id': 'content'}
soup.find('div').get('id')
'content'
You can access tags using attribute notation, too.
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
soup.html.div.h1
<h1>Heading here</h1>
soup.html.div.h1.text
'Heading here'
soup.html.div.next_sibling.next_sibling.attrs
{'id': 'nav'}
Let's try and extract a list of HDSI Faculty from https://datascience.ucsd.edu/about/faculty/faculty/.
A good first step is to use the "inspect element" tool in our web browser.
fac_response = requests.get('https://datascience.ucsd.edu/about/faculty/faculty/')
fac_response
<Response [200]>
soup = bs4.BeautifulSoup(fac_response.text)
It seems like the relevant <div>s for faculty are the ones where the data-entry-type attribute is equal to 'individual'. Let's find all of those.
divs = soup.find_all('div', attrs={'data-entry-type': 'individual'})
divs[0]
<div class="cn-list-row cn-list-item vcard individual faculty lecturers" data-entry-id="229" data-entry-slug="rod-albuyeh" data-entry-type="individual" id="rod-albuyeh"> <div class="cn-entry cn-accordion" id="entry-id-22962704d3a221a3"> <div class="cn-left" style="min-width: 215px;"> <span class="cn-image-style"><span style="display: block; max-width: 100%; width: 215px"><img alt="Photo of Rod Albuyeh" class="cn-image photo" height="215" lazyload="1" loading="lazy" sizes="100vw" srcset="//datascience.ucsd.edu/wp-content/uploads/connections-images/rod-albuyeh/Rod-Albuyeh-Web-07dd8c651b197a11107f1c858ce1e390.jpg 1x" title="Photo of Rod Albuyeh" width="215"/></span></span> </div> <!-- end cn-left--> <div class="cn-right"> <h3 style="border-bottom: #182A48 1px solid; color:#182A48;"><a href="https://datascience.ucsd.edu/about/faculty/faculty/name/rod-albuyeh/" title="Rod Albuyeh"><span class="fn n notranslate"><span class="given-name">Rod</span> <span class="family-name">Albuyeh</span></span></a> </h3><h4 class="title">Lecturer</h4> <div class="cn-excerpt" id="cn-excerpt-22962704d3a221a3"> Albuyeh is Principal Data Scientist at Figure and part-time lecturer at the Halıcıoğlu Data Science Institute at UC San Diego. He received his Ph.D. in Political Science at USC in 2016. His specialties lie in anomaly detection for tabular time-series data and machine learning systems--with applications in marketing, fraud, and credit risk. He is also interested in applying enterprise machine learning approaches to solve problems in the social sciences. Research Interests: Machine Learning, Deployment, Scalable Systems<span class="cn-link-more"><a href="https://datascience.ucsd.edu/about/faculty/faculty/name/rod-albuyeh/">Learn More</a></span> </div> <!--end cn-excerpt--> <div class="cn-detail cn-hide" id="cn-detail-22962704d3a221a3"> <div class="cn-bio" id="cn-bio-22962704d3a221a3"><div class="cn-biography"><p>Albuyeh is Principal Data Scientist at Figure and part-time lecturer at the Halıcıoğlu Data Science Institute at UC San Diego. He received his Ph.D. in Political Science at USC in 2016. His specialties lie in anomaly detection for tabular time-series data and machine learning systems–with applications in marketing, fraud, and credit risk. He is also interested in applying enterprise machine learning approaches to solve problems in the social sciences.</p> <p>Research Interests: Machine Learning, Deployment, Scalable Systems</p> </div> </div> </div> <!--end cn-detail--> </div> <!--end cn-right--> </div> <!-- end cn-entry --> </div>
Within here, we need to extract each faculty member's name. It seems like names are stored in the title attribute within an <a> tag.
divs[0].find('a').get('title')
'Rod Albuyeh'
We can also extract job titles:
divs[0].find('h4').text
'Lecturer'
And bios:
divs[0].find('div', attrs={'class': 'cn-bio'}).text.strip()
'Albuyeh is Principal Data Scientist at Figure and part-time lecturer at the Halıcıoğlu Data Science Institute at UC San Diego.\xa0 He received his Ph.D. in Political Science at USC in 2016.\xa0 His specialties lie in anomaly detection for tabular time-series data and machine learning systems–with applications in marketing, fraud, and credit risk.\xa0 He is also interested in applying enterprise machine\xa0learning approaches to solve problems in the social sciences.\nResearch Interests: Machine Learning, Deployment, Scalable Systems'
Let's create a DataFrame consisting of names and bios for each faculty member.
names = [div.find('a').get('title') for div in divs]
names[:5]
['Rod Albuyeh', 'Ilkay Altintas', 'Mikio Aoi', 'Ery Arias-Castro', 'Vineet Bafna']
titles = [div.find('h4').text if div.find('h4') else '' for div in divs]
bios = [div.find('div', attrs={'class': 'cn-bio'}).text.strip() for div in divs]
faculty = pd.DataFrame().assign(name=names, title=titles, bio=bios)
faculty.head()
| name | title | bio | |
|---|---|---|---|
| 0 | Rod Albuyeh | Lecturer | Albuyeh is Principal Data Scientist at Figure ... |
| 1 | Ilkay Altintas | Chief Data Science Officer, HDSI Founding Facu... | CHIEF DATA SCIENCE OFFICER, SDSC\nIlkay Altint... |
| 2 | Mikio Aoi | Assistant Professor | Dr. Aoi is a computational neuroscientist inte... |
| 3 | Ery Arias-Castro | Professor | Ery Arias-Castro received his Ph.D. in Statist... |
| 4 | Vineet Bafna | Professor | Vineet Bafna, Ph.D., is a Bioinformatics resea... |
Now we have a DataFrame!
faculty[faculty['title'] == 'Lecturer']
| name | title | bio | |
|---|---|---|---|
| 0 | Rod Albuyeh | Lecturer | Albuyeh is Principal Data Scientist at Figure ... |
| 31 | Suraj Rampure | Lecturer | Suraj Rampure is a Lecturer in the Halıcıoğlu ... |
| 42 | Janine Tiefenbruck | Lecturer | Tiefenbruck focuses her mathematics background... |
What if we want to get faculty members' pictures? It seems like we should look at the attributes of an <img> tag.
divs[0].find('img')
<img alt="Photo of Rod Albuyeh" class="cn-image photo" height="215" lazyload="1" loading="lazy" sizes="100vw" srcset="//datascience.ucsd.edu/wp-content/uploads/connections-images/rod-albuyeh/Rod-Albuyeh-Web-07dd8c651b197a11107f1c858ce1e390.jpg 1x" title="Photo of Rod Albuyeh" width="215"/>
def show_picture(name):
idx = names.index(name)
url = divs[idx].find('img').get('srcset')
url = 'https://' + url.strip('/').strip(' 1x')
display(Image(url))
show_picture('Suraj Rampure')

soup.find and soup.find_all are the functions you will use most often.