In [35]:
pd.DataFrame({'train': train, 'valid': valid}, index=index).plot()
plt.xlabel('Depth')
plt.ylabel('Accuracy');

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn-white')
plt.rc('figure', dpi=100, figsize=(7, 5))
plt.rc('font', size=12)
import warnings
warnings.simplefilter('ignore')
When we one-hot encode categorical features, we create several redundant columns.
tips = sns.load_dataset('tips')
tips_features = tips.drop('tip', axis=1)
tips_features.head()
| total_bill | sex | smoker | day | time | size | |
|---|---|---|---|---|---|---|
| 0 | 16.99 | Female | No | Sun | Dinner | 2 |
| 1 | 10.34 | Male | No | Sun | Dinner | 3 |
| 2 | 21.01 | Male | No | Sun | Dinner | 3 |
| 3 | 23.68 | Male | No | Sun | Dinner | 2 |
| 4 | 24.59 | Female | No | Sun | Dinner | 4 |
Aside: You can use pd.get_dummies in EDA, but don't use it for modeling (instead, use OneHotEncoder, which works with Pipelines).
X = pd.get_dummies(tips_features)
X.head()
| total_bill | size | sex_Male | sex_Female | smoker_Yes | smoker_No | day_Thur | day_Fri | day_Sat | day_Sun | time_Lunch | time_Dinner | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 1 | 10.34 | 3 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 2 | 21.01 | 3 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 3 | 23.68 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
| 4 | 24.59 | 4 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 |
Remember that under the hood, LinearRegression() creates a design matrix that has a column of all ones (for the intercept term). Let's add that column above for demonstration.
X['all_ones'] = 1
X.head()
| total_bill | size | sex_Male | sex_Female | smoker_Yes | smoker_No | day_Thur | day_Fri | day_Sat | day_Sun | time_Lunch | time_Dinner | all_ones | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 2 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 1 | 10.34 | 3 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 2 | 21.01 | 3 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 3 | 23.68 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
| 4 | 24.59 | 4 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 |
Now, many of the above columns can be written as linear combinations of other columns!
'sex_Male' – its value is just 'all_ones' - 'sex_Female'.'smoker_Yes' – its value is just 'all_ones' - 'smoker_No'.'time_Lunch' – its value is just 'all_ones' - 'time_Dinner'.'day_Thur' – its value is just 'all_ones' - ('day_Fri' + 'day_Sat' + 'day_Sun').Note that if we get rid of the four redundant columns above, the rank of our design matrix – that is, the number of linearly independent columns it has – does not change (and so the "predictive power" of our features doesn't change either).
np.linalg.matrix_rank(X)
9
np.linalg.matrix_rank(X.drop(columns=['sex_Male', 'smoker_Yes', 'time_Lunch', 'day_Thur']))
9
However, without the redundant columns, there is only a single unique set of optimal parameters $w^*$, and the multicollinearity is no more.
Aside: Most one-hot encoding techniques (including OneHotEncoder) have an in-built drop argument, which allow you to specify that you'd like to drop one column per categorical feature.
pd.get_dummies(tips_features, drop_first=True)
| total_bill | size | sex_Female | smoker_No | day_Fri | day_Sat | day_Sun | time_Dinner | |
|---|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 2 | 1 | 1 | 0 | 0 | 1 | 1 |
| 1 | 10.34 | 3 | 0 | 1 | 0 | 0 | 1 | 1 |
| 2 | 21.01 | 3 | 0 | 1 | 0 | 0 | 1 | 1 |
| 3 | 23.68 | 2 | 0 | 1 | 0 | 0 | 1 | 1 |
| 4 | 24.59 | 4 | 1 | 1 | 0 | 0 | 1 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 239 | 29.03 | 3 | 0 | 1 | 0 | 1 | 0 | 1 |
| 240 | 27.18 | 2 | 1 | 0 | 0 | 1 | 0 | 1 |
| 241 | 22.67 | 2 | 0 | 0 | 0 | 1 | 0 | 1 |
| 242 | 17.82 | 2 | 0 | 1 | 0 | 1 | 0 | 1 |
| 243 | 18.78 | 2 | 1 | 1 | 0 | 0 | 0 | 1 |
244 rows × 8 columns
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(drop='first')
ohe.fit_transform(tips_features[['sex', 'smoker', 'day', 'time']]).toarray()
array([[0., 0., 0., 1., 0., 0.],
[1., 0., 0., 1., 0., 0.],
[1., 0., 0., 1., 0., 0.],
...,
[1., 1., 1., 0., 0., 0.],
[1., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 1., 0.]])
ohe.get_feature_names()
array(['x0_Male', 'x1_Yes', 'x2_Sat', 'x2_Sun', 'x2_Thur', 'x3_Lunch'],
dtype=object)
The above array only has $(2-1) + (2-1) + (4-1) + (2-1) = 6$ columns, rather than $2 + 2 + 4 + 2 = 10$, since we dropped 1 per categorical column in tips_features.
reviews = pd.read_json(open('data/reviews.json'), lines=True)
reviews.head()
| reviewerID | asin | reviewerName | helpful | reviewText | overall | summary | unixReviewTime | reviewTime | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | A1JZFGZEZVWQPY | B00002N674 | Carter H "1amazonreviewer@gmail . com" | [4, 4] | Good USA company that stands behind their prod... | 4 | Great Hoses | 1308614400 | 06 21, 2011 |
| 1 | A32JCI4AK2JTTG | B00002N674 | Darryl Bennett "Fuzzy342" | [0, 0] | This is a high quality 8 ply hose. I have had ... | 5 | Gilmour 10-58050 8-ply Flexogen Hose 5/8-Inch ... | 1402272000 | 06 9, 2014 |
| 2 | A3N0P5AAMP6XD2 | B00002N674 | H B | [2, 3] | It's probably one of the best hoses I've ever ... | 4 | Very satisfied! | 1336176000 | 05 5, 2012 |
| 3 | A2QK7UNJ857YG | B00002N674 | Jason | [0, 0] | I probably should have bought something a bit ... | 5 | Very high quality | 1373846400 | 07 15, 2013 |
| 4 | AS0CYBAN6EM06 | B00002N674 | jimmy | [1, 1] | I bought three of these 5/8-inch Flexogen hose... | 5 | Good Hoses | 1375660800 | 08 5, 2013 |
Goal: Use a review's 'summary' to predict its 'overall' rating.
Note that there are five possible 'overall' rating values – 1, 2, 3, 4, 5 – not just two. As such, this is an instance of multiclass classification.
reviews['overall'].value_counts(normalize=True)
5 0.530214 4 0.254973 3 0.125000 2 0.050708 1 0.039105 Name: overall, dtype: float64
Question: What is the worst possible accuracy we should expect from a ratings classifier, given the above distribution?
CountVectorizer¶Entries in the 'summary' column are not currently quantitative! We can use the bag-of-words encoding to create quantitative features out of each 'summary'. Instead of performing a bag-of-words encoding manually as we did before, we can rely on sklearn's CountVectorizer.
from sklearn.feature_extraction.text import CountVectorizer
example_corp = ['hey hey hey my name is billy',
'hey billy how is your dog billy']
count_vec = CountVectorizer()
count_vec.fit(example_corp)
CountVectorizer()
count_vec learned a vocabulary from the corpus we fit it on.
count_vec.vocabulary_
{'hey': 2,
'my': 5,
'name': 6,
'is': 4,
'billy': 0,
'how': 3,
'your': 7,
'dog': 1}
count_vec.transform(example_corp).toarray()
array([[1, 0, 3, 0, 1, 1, 1, 0],
[2, 1, 1, 1, 1, 0, 0, 1]])
Note that the values in count_vec.vocabulary_ correspond to the positions of the columns in count_vec.transform(example_corp).toarray(), i.e. 'billy' is the first column and 'your' is the last column.
example_corp
['hey hey hey my name is billy', 'hey billy how is your dog billy']
pd.DataFrame(count_vec.transform(example_corp).toarray(),
columns=pd.Series(count_vec.vocabulary_).sort_values().index)
| billy | dog | hey | how | is | my | name | your | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 0 | 1 | 1 | 1 | 0 |
| 1 | 2 | 1 | 1 | 1 | 1 | 0 | 0 | 1 |
Pipeline¶Let's build a Pipeline that takes in summaries and overall ratings and:
CountVectorizer to quantitatively encode summaries.RandomForestClassifier to the data.But first, a train-test split (like always).
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestClassifier
X = reviews['summary']
y = reviews['overall']
X_train, X_test, y_train, y_test = train_test_split(X, y)
pl = Pipeline([
('cv', CountVectorizer()),
('clf', RandomForestClassifier(max_depth=8, n_estimators=7)) # Uses 7 separate decision trees
])
pl.fit(X_train, y_train)
Pipeline(steps=[('cv', CountVectorizer()),
('clf', RandomForestClassifier(max_depth=8, n_estimators=7))])
# Training accuracy
pl.score(X_train, y_train)
0.5306409483624673
# Testing accuracy
pl.score(X_test, y_test)
0.5343580470162749
The accuracy of our random forest is just above 50%, on both the training and testing sets. This doesn't seem much better than just predicting "5 stars" every time!
len(pl.named_steps['cv'].vocabulary_) # Many features, but we are not asking many questions!
5275
GridSearchCV¶We arbitrarily chose max_depth=8 before, but it seems like that isn't working well. Let's perform a grid search to find the max_depth with the best generalization performance.
pl.named_steps
{'cv': CountVectorizer(),
'clf': RandomForestClassifier(max_depth=8, n_estimators=7)}
# Note that we've used the key clf__max_depth, not max_depth
# because max_depth is a hyperparameter of clf, not of pl
hyperparameters = {
'clf__max_depth': np.arange(2, 500, 20)
}
Note that while pl has already been fit, we can still give it to GridSearchCV, which will repeatedly re-fit it during cross-validation.
from sklearn.model_selection import GridSearchCV
# Takes 10+ seconds to run – how many trees are being trained?
grids = GridSearchCV(pl, param_grid=hyperparameters, return_train_score=True)
grids.fit(X_train, y_train)
GridSearchCV(estimator=Pipeline(steps=[('cv', CountVectorizer()),
('clf',
RandomForestClassifier(max_depth=8,
n_estimators=7))]),
param_grid={'clf__max_depth': array([ 2, 22, 42, 62, 82, 102, 122, 142, 162, 182, 202, 222, 242,
262, 282, 302, 322, 342, 362, 382, 402, 422, 442, 462, 482])},
return_train_score=True)
grids.best_params_
{'clf__max_depth': 162}
Recall, fit GridSearchCV objects are estimators on their own as well. This means we can compute the training and testing accuracies of the "best" random forest directly:
# Training accuracy
grids.score(X_train, y_train)
0.8393610608800482
# Testing accuracy
grids.score(X_test, y_test)
0.5732368896925859
Still not much better on the testing set! 🤷
Below, we plot how training and validation accuracy varied with tree depth. Note that the $y$-axis here is accuracy, and that larger accuracies are better (unlike with RMSE, where smaller was better).
index = grids.param_grid['clf__max_depth']
train = grids.cv_results_['mean_train_score']
valid = grids.cv_results_['mean_test_score']
pd.DataFrame({'train': train, 'valid': valid}, index=index).plot()
plt.xlabel('Depth')
plt.ylabel('Accuracy');
Unsurprisingly, training accuracy kept increasing, while validation accuracy leveled off around a depth of ~100.
Repeat the previous paragraph many, many times.
One night, the shepherd boy sees a real wolf approaching the flock and calls out, "Wolf!" The villagers refuse to be fooled again and stay in their houses. The hungry wolf turns the flock into lamb chops. The town goes hungry. Panic ensues.
Some questions to think about:
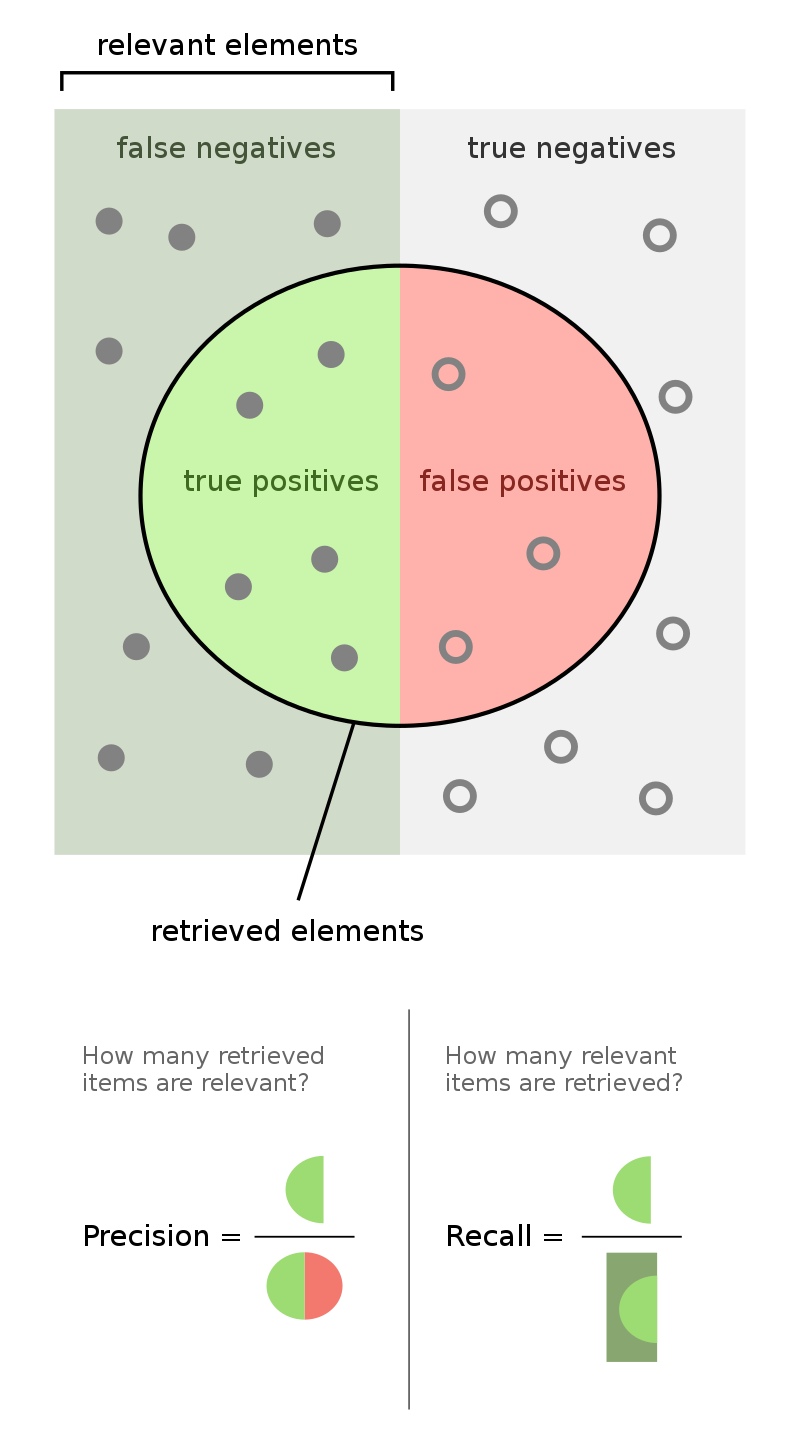
Below, we present a confusion matrix, which summarizes the four possible outcomes of the wolf classifier.

When performing binary classification, there are four possible outcomes.
(Note: A "positive prediction" is a prediction of 1, and a "negative prediction" is a prediction of 0.)
| Outcome of Prediction | Definition | True Class |
|---|---|---|
| True positive (TP) ✅ | The predictor correctly predicts the positive class. | P |
| False negative (FN) ❌ | The predictor incorrectly predicts the negative class. | P |
| True negative (TN) ✅ | The predictor correctly predicts the negative class. | N |
| False positive (FP) ❌ | The predictor incorrectly predicts the positive class. | N |
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN ✅ | FP ❌ |
| Actually Positive | FN ❌ | TP ✅ |
sklearn's confusion matrices are (but differently than in the wolf example).Note that in the four acronyms – TP, FN, TN, FP – the first letter is whether the prediction is correct, and the second letter is what the prediction is.
The results of 100 UCSD Health COVID tests are given below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 90 ✅ | FP = 1 ❌ |
| Actually Positive | FN = 8 ❌ | TP = 1 ✅ |
🤔 Question: What is the accuracy of the test?
🙋 Answer: $$\text{accuracy} = \frac{TP + TN}{TP + FP + FN + TN} = \frac{1 + 90}{100} = 0.91$$
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 90 ✅ | FP = 1 ❌ |
| Actually Positive | FN = 8 ❌ | TP = 1 ✅ |
🤔 Question: What proportion of individuals who actually have COVID did the test identify?
🙋 Answer: $\frac{1}{1 + 8} = \frac{1}{9} \approx 0.11$
More generally, the recall of a binary classifier is the proportion of actually positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{recall} = \frac{TP}{TP + FN}$$To compute recall, look at the bottom (positive) row of the above confusion matrix.
🤔 Question: Can you design a "COVID test" with perfect recall?
🙋 Answer: Yes – just predict that everyone has COVID!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
Like accuracy, recall on its own is not a perfect metric. Even though the classifier we just created has perfect recall, it has 91 false positives!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
The precision of a binary classifier is the proportion of predicted positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{precision} = \frac{TP}{TP + FP}$$To compute precision, look at the right (positive) column of the above confusion matrix.
🤔 Question: When might high precision be more important than high recall?
🙋 Answer: For instance, in deciding whether or not someone committed a crime. Here, false positives are really bad – they mean that an innocent person is charged!
🤔 Question: When might high recall be more important than high precision?
🙋 Answer: For instance, in medical tests. Here, false negatives are really bad – they mean that someone's disease goes undetected!
Consider the confusion matrix shown below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 22 ✅ | FP = 2 ❌ |
| Actually Positive | FN = 23 ❌ | TP = 18 ✅ |
What is the accuracy of the above classifier? The precision? The recall?
After calculating all three on your own, click below to see the answers.
CountVectorizer transformer can be used to perform the bag-of-words encoding.