import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
plt.style.use('seaborn-white')
plt.rc('figure', dpi=100, figsize=(7, 5))
plt.rc('font', size=12)
import warnings
warnings.simplefilter('ignore')
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 90 ✅ | FP = 1 ❌ |
| Actually Positive | FN = 8 ❌ | TP = 1 ✅ |
🤔 Question: What proportion of individuals who actually have COVID did the test identify?
🙋 Answer: $\frac{1}{1 + 8} = \frac{1}{9} \approx 0.11$
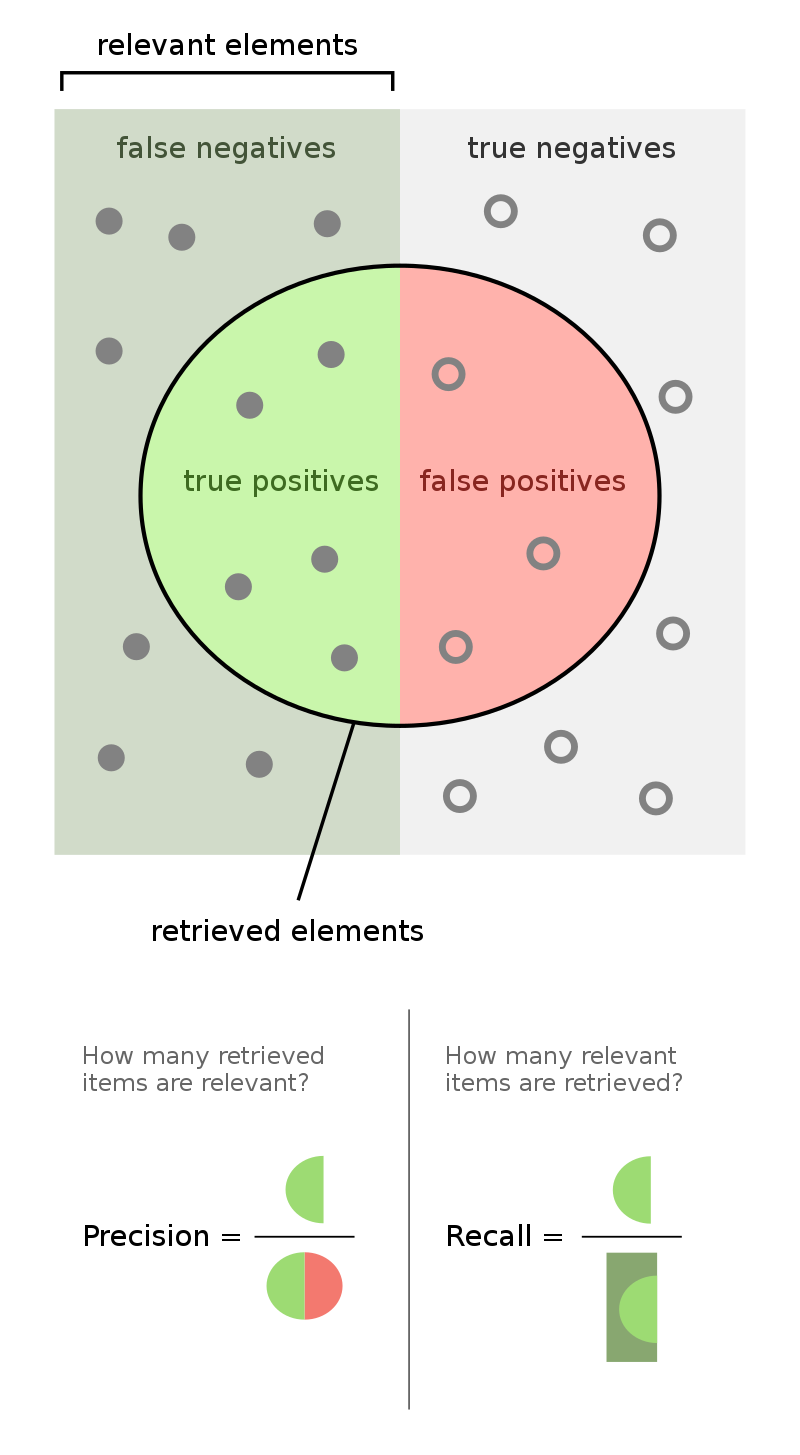
More generally, the recall of a binary classifier is the proportion of actually positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{recall} = \frac{TP}{TP + FN}$$To compute recall, look at the bottom (positive) row of the above confusion matrix.
🤔 Question: Can you design a "COVID test" with perfect recall?
🙋 Answer: Yes – just predict that everyone has COVID!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
Like accuracy, recall on its own is not a perfect metric. Even though the classifier we just created has perfect recall, it has 91 false positives!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
The precision of a binary classifier is the proportion of predicted positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{precision} = \frac{TP}{TP + FP}$$To compute precision, look at the right (positive) column of the above confusion matrix.
🤔 Question: When might high precision be more important than high recall?
🙋 Answer: For instance, in deciding whether or not someone committed a crime. Here, false positives are really bad – they mean that an innocent person is charged!
🤔 Question: When might high recall be more important than high precision?
🙋 Answer: For instance, in medical tests. Here, false negatives are really bad – they mean that someone's disease goes undetected!
Consider the confusion matrix shown below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 22 ✅ | FP = 2 ❌ |
| Actually Positive | FN = 23 ❌ | TP = 18 ✅ |
What is the accuracy of the above classifier? The precision? The recall?
After calculating all three on your own, click below to see the answers.
End of Final Exam content! 🎉
(Note that the remaining content is still relevant for Project 5.)
The Wisconsin breast cancer dataset (WBCD) is a commonly-used dataset for demonstrating binary classification. It is built into sklearn.datasets.
from sklearn.datasets import load_breast_cancer
loaded = load_breast_cancer() # explore the value of `loaded`!
data = loaded['data']
labels = 1 - loaded['target']
cols = loaded['feature_names']
bc = pd.DataFrame(data, columns=cols)
bc.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
5 rows × 30 columns
1 stands for "malignant", i.e. cancerous, and 0 stands for "benign", i.e. safe.
labels[:5]
array([1, 1, 1, 1, 1])
pd.Series(labels).value_counts(normalize=True)
0 0.627417 1 0.372583 dtype: float64
Our goal is to use the features in bc to predict labels.
Logistic regression is a linear classification? technique that builds upon linear regression. It models the probability of belonging to class 1, given a feature vector:
$$P(y = 1 | \vec{x}) = \sigma (\underbrace{w_0 + w_1 x^{(1)} + w_2 x^{(2)} + ... + w_d x^{(d)}}_{\text{linear regression model}})$$Here, $\sigma(t) = \frac{1}{1 + e^{-t}}$ is the sigmoid function; its outputs are between 0 and 1 (which means they can be interpreted as probabilities).
🤔 Question: Suppose our logistic regression model predicts the probability that a tumor is malignant is 0.75. What class do we predict – malignant or benign? What if the predicted probability is 0.3?
🙋 Answer: We have to pick a threshold (e.g. 0.5)!
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(bc, labels)
clf = LogisticRegression()
clf.fit(X_train, y_train)
LogisticRegression()
How did clf come up with 1s and 0s?
clf.predict(X_test)
array([0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1,
1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1,
1, 1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0,
1, 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1,
0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0])
It turns out that the predicted labels come from applying a threshold of 0.5 to the predicted probabilities. We can access the predicted probabilities via the predict_proba method:
# [:, 1] refers to the predicted probabilities for class 1
clf.predict_proba(X_test)[:, 1]
array([2.20253638e-02, 1.35994732e-03, 2.89690100e-03, 9.78234450e-01,
5.31942714e-04, 4.10782587e-04, 6.74575167e-03, 3.24595405e-02,
9.99774556e-01, 4.61849754e-02, 5.54972341e-01, 1.11305800e-03,
9.99109588e-01, 6.40848507e-04, 9.99999837e-01, 9.99948589e-01,
5.44235548e-03, 9.46643645e-01, 1.00000000e+00, 1.00000000e+00,
8.16338885e-03, 5.66155305e-01, 9.99898049e-01, 3.64573338e-04,
9.98766289e-01, 2.72194093e-01, 1.63366135e-03, 9.99999955e-01,
3.86343681e-03, 4.17546476e-02, 9.99997345e-01, 7.39683899e-03,
2.74247221e-02, 1.02945866e-01, 9.88146351e-01, 2.51457420e-01,
8.66723127e-05, 9.98471760e-01, 1.45032212e-01, 4.96494397e-02,
8.26077421e-01, 8.85240835e-02, 1.00000000e+00, 9.90204278e-01,
9.99999984e-01, 9.99999998e-01, 8.42681426e-02, 3.12773885e-03,
9.99435808e-01, 2.17577529e-02, 9.51928651e-01, 3.76424830e-04,
2.43889826e-04, 4.64243442e-03, 9.32811417e-01, 5.91992690e-03,
9.99999590e-01, 9.99999927e-01, 1.10906216e-02, 9.86177784e-01,
6.50872472e-02, 3.82930620e-01, 1.36249392e-02, 3.05705040e-02,
3.71223922e-01, 2.75140395e-01, 9.92734259e-01, 1.00000000e+00,
4.11250789e-03, 6.11650617e-01, 5.25961629e-05, 9.99990512e-01,
9.99997644e-01, 9.60612923e-01, 9.31482574e-01, 4.18540866e-03,
1.91030023e-02, 1.14805643e-03, 7.71859380e-02, 6.99839600e-01,
9.99992534e-01, 9.07302216e-05, 2.98460897e-01, 7.45875585e-02,
9.99999997e-01, 4.03995188e-03, 1.07041490e-02, 1.00000000e+00,
5.18829429e-05, 1.34351397e-02, 2.87568119e-02, 5.41969228e-02,
2.77578204e-03, 1.75731323e-01, 1.56303788e-02, 9.99703471e-01,
9.99999979e-01, 1.00000000e+00, 6.33574300e-04, 1.43014823e-02,
2.10960841e-01, 9.99999998e-01, 1.40726055e-01, 1.05431029e-02,
2.85531651e-04, 1.75123805e-04, 9.94463636e-01, 9.99999308e-01,
2.84718870e-04, 9.99344959e-01, 2.76881549e-05, 3.23738934e-02,
9.84014697e-01, 1.00000000e+00, 6.41383013e-01, 6.48610700e-04,
1.27593922e-04, 2.78023041e-01, 2.95234529e-02, 1.57136962e-03,
5.03558182e-04, 9.90342454e-01, 9.99999997e-01, 9.99450279e-01,
9.79201002e-01, 4.38178543e-02, 1.54248916e-03, 1.16559608e-02,
1.64950345e-02, 3.15756658e-04, 4.75411755e-03, 9.99984802e-01,
2.60736441e-04, 3.39005750e-03, 4.83542411e-03, 1.00000000e+00,
1.89371194e-01, 2.43088459e-02, 1.94186018e-02, 4.45345885e-04,
2.42394688e-04, 1.06612199e-01, 4.55846092e-03])
Note that our model still has $w^*$s:
clf.intercept_
array([-0.22028652])
clf.coef_
array([[-1.14981798, -0.50150065, -0.26873902, 0.02075917, 0.03860407,
0.19056491, 0.2830736 , 0.11948749, 0.05917228, 0.00894889,
-0.06649598, -0.38466513, -0.2996452 , 0.08591204, 0.00396817,
0.04383983, 0.06525643, 0.01572042, 0.01654787, 0.00426983,
-1.31811266, 0.57822617, 0.2908566 , 0.01317504, 0.06288459,
0.55746945, 0.73464736, 0.21157 , 0.16449191, 0.04794465]])
Let's see how well our model does on the test set.
from sklearn import metrics
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)
0.9300699300699301
metrics.precision_score(y_test, y_pred)
0.9259259259259259
metrics.recall_score(y_test, y_pred)
0.8928571428571429
Which metric is more important for this task – precision or recall?
metrics.confusion_matrix(y_test, y_pred)
array([[83, 4],
[ 6, 50]])
metrics.plot_confusion_matrix(clf, X_test, y_test);

🤔 Question: Suppose we choose a threshold higher than 0.5. What will happen to our model's precision and recall?
🙋 Answer: Precision will increase, while recall will decrease*.
Similarly, if we decrease our threshold, our model's precision will decrease, while its recall will increase.
The classification threshold is not actually a hyperparameter of LogisticRegression, because the threshold doesn't change the coefficients ($w^*$s) of the logistic regression model itself (see this article for more details).
As such, if we want to imagine how our predicted classes would change with thresholds other than 0.5, we need to manually threshold.
thresholds = np.arange(0, 1.01, 0.01)
precisions = np.array([])
recalls = np.array([])
for t in thresholds:
y_pred = clf.predict_proba(X_test)[:, 1] >= t
precisions = np.append(precisions, metrics.precision_score(y_test, y_pred))
recalls = np.append(recalls, metrics.recall_score(y_test, y_pred))
Let's visualize the results in plotly, which is interactive.
px.line(x=thresholds, y=precisions,
labels={'x': 'Threshold', 'y': 'Precision'}, title='Precision vs. Threshold', width=1000, height=600)
px.line(x=thresholds, y=recalls,
labels={'x': 'Threshold', 'y': 'Recall'}, title='Recall vs. Threshold', width=1000, height=600)
px.line(x=recalls, y=precisions, hover_name=thresholds,
labels={'x': 'Recall', 'y': 'Precision'}, title='Precision vs. Recall')
The above curve is called a precision-recall (or PR) curve.
🤔 Question: Based on the PR curve above, what threshold would you choose?
If we care equally about a model's precision $PR$ and recall $RE$, we can combine the two using a single metric called the F1-score:
$$\text{F1-score} = \text{harmonic mean}(PR, RE) = 2\frac{PR \cdot RE}{PR + RE}$$pr = metrics.precision_score(y_test, clf.predict(X_test))
re = metrics.recall_score(y_test, clf.predict(X_test))
2 * pr * re / (pr + re)
0.9090909090909091
metrics.f1_score(y_test, clf.predict(X_test))
0.9090909090909091
Both F1-score and accuracy are overall measures of a binary classifier's performance. But remember, accuracy is misleading in the presence of class imbalance, and doesn't take into account the kinds of errors the classifier makes.
metrics.accuracy_score(y_test, clf.predict(X_test))
0.9300699300699301
We just scratched the surface! This excellent table from Wikipedia summarizes the many other metrics that exist.
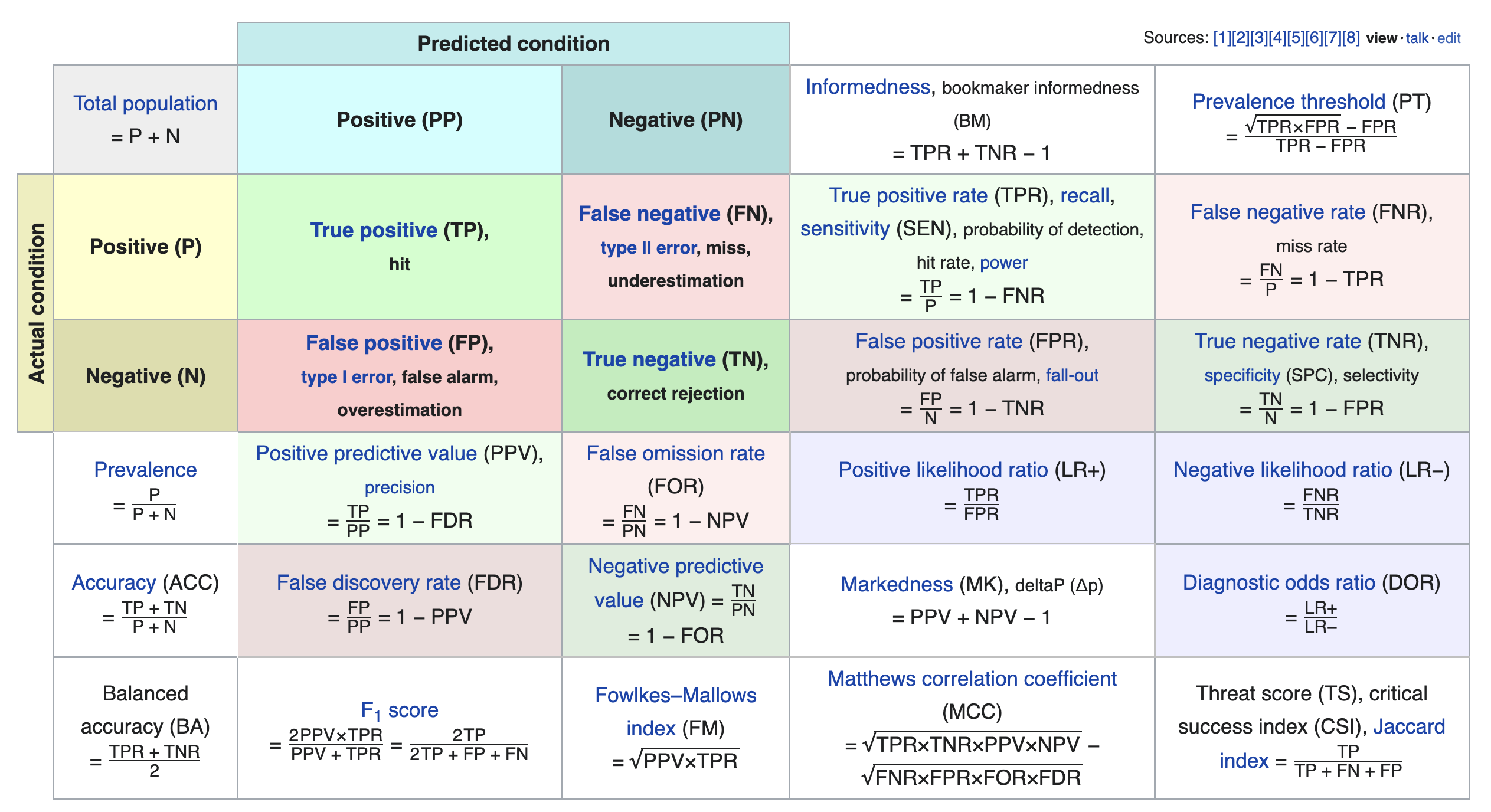
If you're interested in exploring further, a good next metric to look at is true negative rate (i.e. specificity), which is the analogue of recall for true negatives.
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) is a "black-box" model that estimates the likelihood that someone who has commited a crime will recidivate (commit another crime).
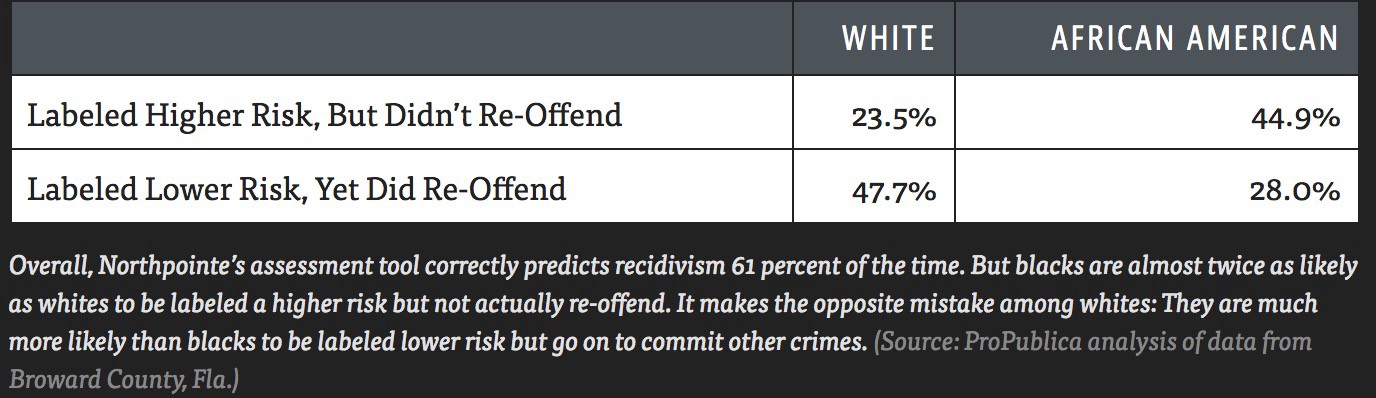
Propublica found that the model's false positive rate is higher for African-Americans than it is for White Americans, and that its false negative rate is lower for African-Americans than it is for White Americans.
Note:
$$PPV = \text{precision} = \frac{TP}{TP+FP},\:\:\:\:\:\: TPR = \text{recall} = \frac{TP}{TP + FN}, \:\:\:\:\:\: FPR = \frac{FP}{FP+TN}$$Remember, our models learn patterns from the training data. Various sources of bias may be present within training data:
A 2015 study examined the image queries of vocations and the gender makeup in the search results. Since 2015, the behavior of Google Images has been improved.
In 2015, a Google Images search for "nurse" returned...

Search for "nurse" now, what do you see?
In 2015, a Google Images search for "doctor" returned...

Search for "doctor" now, what do you see?

Excerpts:
"male-dominated professions tend to have even more men in their results than would be expected if the proportions reflected real-world distributions.
"People’s existing perceptions of gender ratios in occupations are quite accurate, but that manipulated search results have an effect on perceptions."