In 2015, a Google Images search for "nurse" returned...

Search for "nurse" now, what do you see?
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px
plt.style.use('seaborn-white')
plt.rc('figure', dpi=100, figsize=(7, 5))
plt.rc('font', size=12)
import warnings
warnings.simplefilter('ignore')
A 2015 study examined the image queries of vocations and the gender makeup in the search results. Since 2015, the behavior of Google Images has been improved.
In 2015, a Google Images search for "nurse" returned...
Search for "nurse" now, what do you see?
In 2015, a Google Images search for "doctor" returned...

Search for "doctor" now, what do you see?

Excerpts:
"male-dominated professions tend to have even more men in their results than would be expected if the proportions reflected real-world distributions.
"People’s existing perceptions of gender ratios in occupations are quite accurate, but that manipulated search results have an effect on perceptions."
LendingClub is a "peer-to-peer lending company"; they used to publish a dataset describing the loans that they approved (fortunately, we downloaded it while it was available).
'tag': whether loan was repaid in full (1.0) or defaulted (0.0)'loan_amnt': amount of the loan in dollars'emp_length': number of years employed'home_ownership': whether borrower owns (1.0) or rents (0.0)'inq_last_6mths': number of credit inquiries in last six months'revol_bal': revolving balance on borrows accounts'age': age in years of the borrower (protected attribute)loans = pd.read_csv('data/loan_vars1.csv', index_col=0)
loans.head()
| loan_amnt | emp_length | home_ownership | inq_last_6mths | revol_bal | age | tag | |
|---|---|---|---|---|---|---|---|
| 268309 | 6400.0 | 0.0 | 1.0 | 1.0 | 899.0 | 22.0 | 0.0 |
| 301093 | 10700.0 | 10.0 | 1.0 | 0.0 | 29411.0 | 19.0 | 0.0 |
| 1379211 | 15000.0 | 10.0 | 1.0 | 2.0 | 9911.0 | 48.0 | 0.0 |
| 486795 | 15000.0 | 10.0 | 1.0 | 2.0 | 15883.0 | 35.0 | 0.0 |
| 1481134 | 22775.0 | 3.0 | 1.0 | 0.0 | 17008.0 | 39.0 | 0.0 |
The total amount of money loaned was over 5 billion dollars!
loans['loan_amnt'].sum()
5706507225.0
loans.shape[0]
386772
'tag'¶Let's build a classifier that predicts whether or not a loan was paid in full. If we were a bank, we could use our trained classifier to determine whether to approve someone for a loan!
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
X = loans.drop('tag', axis=1)
y = loans.tag
X_train, X_test, y_train, y_test = train_test_split(X, y)
clf = RandomForestClassifier(n_estimators=50)
clf.fit(X_train, y_train)
RandomForestClassifier(n_estimators=50)
Recall, a prediction of 1 means that we predict that the loan will be paid in full.
y_pred = clf.predict(X_test)
y_pred
array([0., 0., 0., ..., 0., 0., 0.])
clf.score(X_test, y_test)
0.7125231402480015
from sklearn import metrics
metrics.plot_confusion_matrix(clf, X_test, y_test);

Precision describes the proportion of loans that were approved that would have been paid back.
metrics.precision_score(y_test, y_pred)
0.7719863151539545
If we subtract the precision from 1, we get the proportion of loans that were approved that would not have been paid back. This is known as the false discovery rate.
$$\frac{FP}{TP + FP} = 1 - \text{precision}$$1 - metrics.precision_score(y_test, y_pred)
0.22801368484604545
Recall describes the proportion of loans that would have been paid back that were actually approved.
metrics.recall_score(y_test, y_pred)
0.7334608030592734
If we subtract the recall from 1, we get the proportion of loans that would have been paid back that were denied. This is known as the false negative rate.
$$\frac{FN}{TP + FN} = 1 - \text{recall}$$1 - metrics.recall_score(y_test, y_pred)
0.2665391969407266
From both the perspective of the bank and the lendee, a high false negative rate is bad!
results = X_test
results['age_bracket'] = results['age'].apply(lambda x: 5 * (x // 5 + 1))
results['prediction'] = y_pred
results['tag'] = y_test
(
results
.groupby('age_bracket')
.apply(lambda x: 1 - metrics.recall_score(x['tag'], x['prediction']))
.plot(kind='bar', title='False Negative Rate by Age Group')
);

results['is_young'] = (results.age < 25).replace({True: 'young', False: 'old'})
First, let's compute the proportion of loans that were approved in each group. If these two numbers are the same, $C$ achieves demographic parity.
results.groupby('is_young')['prediction'].mean().to_frame()
| prediction | |
|---|---|
| is_young | |
| old | 0.686767 |
| young | 0.298131 |
$C$ evidently does not achieve demographic parity – older people are approved for loans far more often! Note that this doesn't factor in whether they were correctly approved or incorrectly approved.
Now, let's compute the accuracy of $C$ in each group. If these two numbers are the same, $C$ achieves accuracy parity.
(
results
.groupby('is_young')
.apply(lambda x: metrics.accuracy_score(x['tag'], x['prediction']))
.rename('accuracy')
.to_frame()
)
| accuracy | |
|---|---|
| is_young | |
| old | 0.728456 |
| young | 0.677486 |
Hmm... These numbers look much more similar than before!
Let's run a permutation test to see if the difference in accuracy is significant.
obs = results.groupby('is_young').apply(lambda x: metrics.accuracy_score(x['tag'], x['prediction'])).diff().iloc[-1]
obs
-0.05097027305141033
diff_in_acc = []
for _ in range(100):
s = (
results[['is_young', 'prediction', 'tag']]
.assign(is_young=results.is_young.sample(frac=1.0, replace=False).reset_index(drop=True))
.groupby('is_young')
.apply(lambda x: metrics.accuracy_score(x['tag'], x['prediction']))
.diff()
.iloc[-1]
)
diff_in_acc.append(s)
plt.figure(figsize=(10, 5))
pd.Series(diff_in_acc).plot(kind='hist', ec='w', density=True, bins=15, title='Difference in Accuracy (Young - Old)')
plt.axvline(x=obs, color='red', label='observed difference in accuracy')
plt.legend(loc='upper left');

It seems like the difference in accuracy across the two groups is significant, despite being only ~6%. Thus, $C$ likely does not achieve accuracy parity.
Not only should we use 'age' to determine whether or not to approve a loan, but we also shouldn't use other features that are strongly correlated with 'age', like 'emp_length'.
loans
| loan_amnt | emp_length | home_ownership | inq_last_6mths | revol_bal | age | tag | |
|---|---|---|---|---|---|---|---|
| 268309 | 6400.0 | 0.0 | 1.0 | 1.0 | 899.0 | 22.0 | 0.0 |
| 301093 | 10700.0 | 10.0 | 1.0 | 0.0 | 29411.0 | 19.0 | 0.0 |
| 1379211 | 15000.0 | 10.0 | 1.0 | 2.0 | 9911.0 | 48.0 | 0.0 |
| 486795 | 15000.0 | 10.0 | 1.0 | 2.0 | 15883.0 | 35.0 | 0.0 |
| 1481134 | 22775.0 | 3.0 | 1.0 | 0.0 | 17008.0 | 39.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 466121 | 5000.0 | 1.0 | 0.0 | 0.0 | 8905.0 | 23.0 | 1.0 |
| 1354376 | 2100.0 | 10.0 | 1.0 | 0.0 | 14740.0 | 38.0 | 1.0 |
| 1150493 | 5000.0 | 1.0 | 1.0 | 0.0 | 3842.0 | 52.0 | 1.0 |
| 686485 | 6000.0 | 10.0 | 0.0 | 0.0 | 6529.0 | 36.0 | 1.0 |
| 342901 | 15000.0 | 8.0 | 1.0 | 1.0 | 16060.0 | 39.0 | 1.0 |
386772 rows × 7 columns
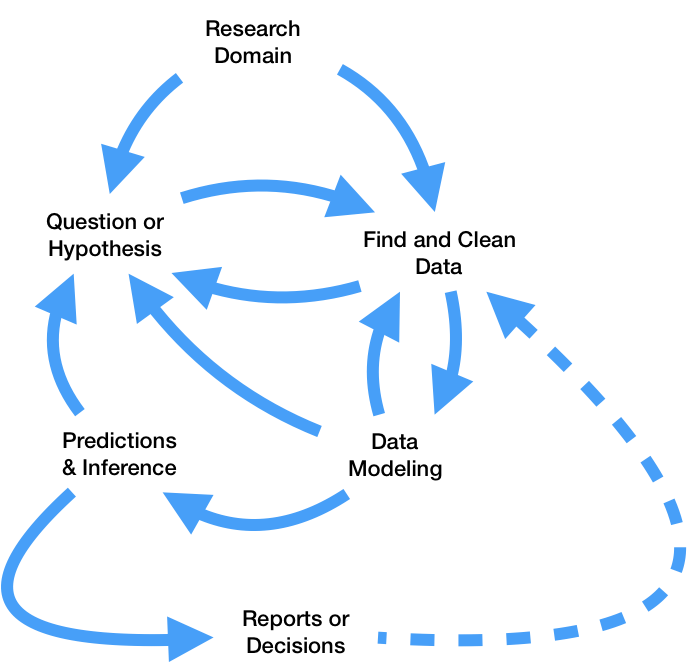
In this course, you...
Now, you...
We learnt a lot this quarter.
pandasscikit-learnThis course would not have been possible without:
Our 11 tutors: Nicole Brye, Aven Huang, Shubham Kaushal, Karthikeya Manchala, Yash Potdar, Costin Smiliovici, Anjana Sriram, Ruojia Tao, Du Xiang, Sheng Yang, and Winston Yu.
Don't be a stranger: dsc80.com/staff.
Apply to be a tutor in the future! Learn more here.