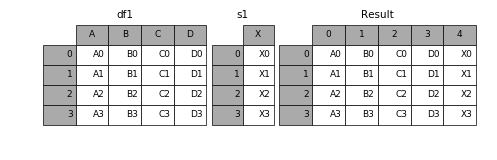
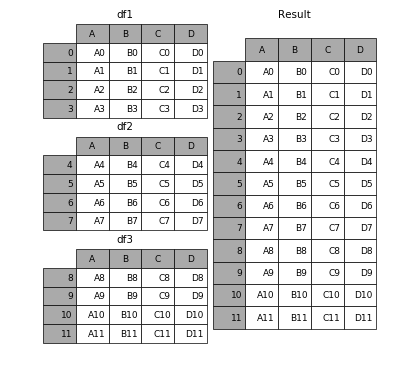
Concatenating vertically¶
- The
pd.concatfunction combines DataFrame and Series objects. - By default, the rows of objects are stacked on top of one another.
pd.concathas many options; we'll learn some of them here, and you'll discover the others by reading the documentation.