In [28]:
show_picture('Tauhidur Rahman')

import pandas as pd
import numpy as np
import os
import requests
import json
import bs4
from IPython.display import display, Image
BeautifulSoup objects¶bs4.BeautifulSoup takes in a string or file-like object representing HTML (markup) and returns a parsed document.html_string = '''
<html>
<body>
<div id="content">
<h1>Heading here</h1>
<p>My First paragraph</p>
<p>My <em>second</em> paragraph</p>
<hr>
</div>
<div id="nav">
<ul>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</div>
</body>
</html>
'''.strip()
soup = bs4.BeautifulSoup(html_string)
type(soup)
bs4.BeautifulSoup
The most common methods you'll use to find tags in a soup object are:
soup.find(tag), which finds the first instance of a tag (the first one on the page, i.e. the first one that DFS sees).soup.find(name=None, attrs={}, recursive=True, text=None, **kwargs).soup.find_all(tag), which finds all instances of a tag.find_all¶find_all returns a list of all matches.
soup.find_all('div')
[<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>, <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>]
soup.find_all('li')
[<li>item 1</li>, <li>item 2</li>, <li>item 3</li>]
[x.text for x in soup.find_all('li')]
['item 1', 'item 2', 'item 3']
text attribute of a tag element gets the text between the opening and closing tags.attrs attribute lists all attributes of a tag.get(key) method gets the value of a tag attribute.soup.find('p')
<p>My First paragraph</p>
soup.find('p').text
'My First paragraph'
soup.find('div')
<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>
soup.find('div').attrs
{'id': 'content'}
soup.find('div').get('id')
'content'
The get method must be called directly on the node that contains the attribute you're looking for.
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
# While there are multiple 'id' attributes, none of them are in the <html> tag at the top.
soup.get('id')
soup.find('div').get('id')
'content'
Let's try and extract a list of HDSI Faculty from https://datascience.ucsd.edu/about/faculty/faculty/.
A good first step is to use the "inspect element" tool in our web browser.
fac_response = requests.get('https://datascience.ucsd.edu/faculty/')
fac_response
<Response [200]>
soup = bs4.BeautifulSoup(fac_response.text)
It seems like the relevant <div>s for faculty are the ones where the data-entry-type attribute is equal to 'individual'. Let's find all of those.
divs = soup.find_all('div', attrs={'class': 'vc_custom_heading vc_gitem-post-data vc_gitem-post-data-source-post_title'})
divs[0]
<div class="vc_custom_heading vc_gitem-post-data vc_gitem-post-data-source-post_title"> <h4 style="text-align: left"><a href="https://www-physics.ucsd.edu/Directory/Person/1" target="_blank">Henry Abarbanel</a></h4> </div>
Within here, we need to extract each faculty member's name. It seems like names are stored as text within the <a> tag.
divs[0].find('a').text
'Henry Abarbanel'
We can also extract job titles:
divs1 = soup.find_all('div', attrs={'class': 'vc_gitem-align-left fields'})
divs1[0]
<div class="vc_gitem-align-left fields"> <div class="field pendari_people_title">Distinguished Professor</div> </div>
divs1 = soup.find_all('div', attrs={'class': 'field pendari_people_title'})
divs1[0].text
'Distinguished Professor'
Let's create a DataFrame consisting of names and job titles for each faculty member.
names = [div.find('a').text for div in divs]
names
['Henry Abarbanel', 'Ilkay Altintas', 'Tiffany Amariuta', 'Mikio Aoi', 'Ery Arias-Castro', 'Vineet Bafna', 'Mikhail Belkin', 'Jelena Bradic', 'Henrik Christensen', 'Alex Cloninger', 'Anders Dale', 'David Danks', 'Virginia de Sa', 'Justin Eldridge', 'Shannon Ellis', 'Yoav Freund', 'R Stuart Geiger', 'Nigel Goldenfeld', 'Rajesh Gupta', 'Mike Holst', 'Albert Hsiao', 'Zhiting Hu', 'Biwei Huang', 'Tara Javidi', 'Haojian Jin', 'Young-Han Kim', 'Rob Knight', 'Arun Kumar', 'Marina Langlois', 'Soohyun Nam Liao', 'Yian Ma', 'Arya Mazumdar', 'Julian McAuley', 'Gal Mishne', 'Eran Mukamel', 'Dimitris Politis', 'Georgio Quer', 'Tauhidur Rahman', 'Suraj Rampure', 'Margaret “Molly” Roberts', 'Rayan Saab', 'Barna Saha', 'Babak Salimi', 'Armin Schwartzman', 'Terrence ‘Terry’ Sejnowski', 'Jingbo Shang', 'Jack Silberman', 'Benjamin Smarr', 'Shankar Subramaniam', 'George Sugihara', 'Janine Tiefenbruck', 'Berk Ustun', 'Bradley Voytek', 'Yusu Wang', 'Duncan Watson-Parris', 'Lily Weng', 'Frank Wuerthwein', 'Ronghui (Lily) Xu', 'Rose Yu', 'Hao Zhang', 'Yuhua Zhu']
# titles = []
# for div in divs:
# h4 = div.find('h4')
# if h4:
# titles.append(h4.text)
# else:
# titles.append('')
titles = [div.text for div in divs1]
titles
['Distinguished Professor', 'SDSC Chief Data Science Officer & HDSI Founding Faculty Fellow', 'Assistant Professor', 'Assistant Professor', 'Professor', 'Professor', 'Professor', 'Professor', 'Distinguished Scientist, Professor', 'Associate Professor', 'Distinguished Scientist, Professor', 'Professor', 'Professor, HDSI Associate Director', 'Assistant Teaching Professor', 'Associate Teaching Professor', 'Professor', 'Assistant Professor', 'Distinguished Professor', 'Distinguished Professor, HDSI Founding Director', 'Professor', 'Associate Professor', 'Assistant Professor', 'Assistant Professor', 'Professor & HDSI Founding Faculty Fellow', 'Assistant Professor', 'Professor', 'Professor', 'Associate Professor, HDSI Faculty Fellow', 'Lecturer', 'Assistant Teaching Professor', 'Assistant Professor', 'Associate Professor', 'Professor', 'Assistant Professor', 'Associate Professor', 'Distinguished Professor, HDSI Associate Director', 'Lecturer', 'Assistant Professor', 'Lecturer', 'Professor', 'Associate Professor', 'Associate Professor', 'Assistant Professor', 'Professor', 'Distinguished Professor', 'Assistant Professor', 'Lecturer', 'Assistant Professor', 'Distinguished Professor', 'Distinguished Professor', 'Lecturer', 'Assistant Professor', 'Professor & HDSI Founding Faculty Fellow', 'Professor', 'Assistant Professor', 'Assistant Professor', 'Professor/ Director of SDSC', 'Professor', 'Assistant Professor', 'Assistant Professor', 'Assistant Professor']
faculty = pd.DataFrame().assign(name=names, title=titles)
faculty.head()
| name | title | |
|---|---|---|
| 0 | Henry Abarbanel | Distinguished Professor |
| 1 | Ilkay Altintas | SDSC Chief Data Science Officer & HDSI Foundin... |
| 2 | Tiffany Amariuta | Assistant Professor |
| 3 | Mikio Aoi | Assistant Professor |
| 4 | Ery Arias-Castro | Professor |
Now we have a DataFrame!
faculty[faculty['title'] == 'Professor']
| name | title | |
|---|---|---|
| 4 | Ery Arias-Castro | Professor |
| 5 | Vineet Bafna | Professor |
| 6 | Mikhail Belkin | Professor |
| 7 | Jelena Bradic | Professor |
| 11 | David Danks | Professor |
| 15 | Yoav Freund | Professor |
| 19 | Mike Holst | Professor |
| 25 | Young-Han Kim | Professor |
| 26 | Rob Knight | Professor |
| 32 | Julian McAuley | Professor |
| 39 | Margaret “Molly” Roberts | Professor |
| 43 | Armin Schwartzman | Professor |
| 53 | Yusu Wang | Professor |
| 57 | Ronghui (Lily) Xu | Professor |
What if we want to get faculty members' pictures? It seems like we should look at the attributes of an <img> tag.
def show_picture(name):
idx = names.index(name)
imgs = soup.find_all('img', attrs={'class': 'vc_gitem-zone-img'})
url = imgs[idx].get('src')
display(Image(url))
show_picture('Tauhidur Rahman')
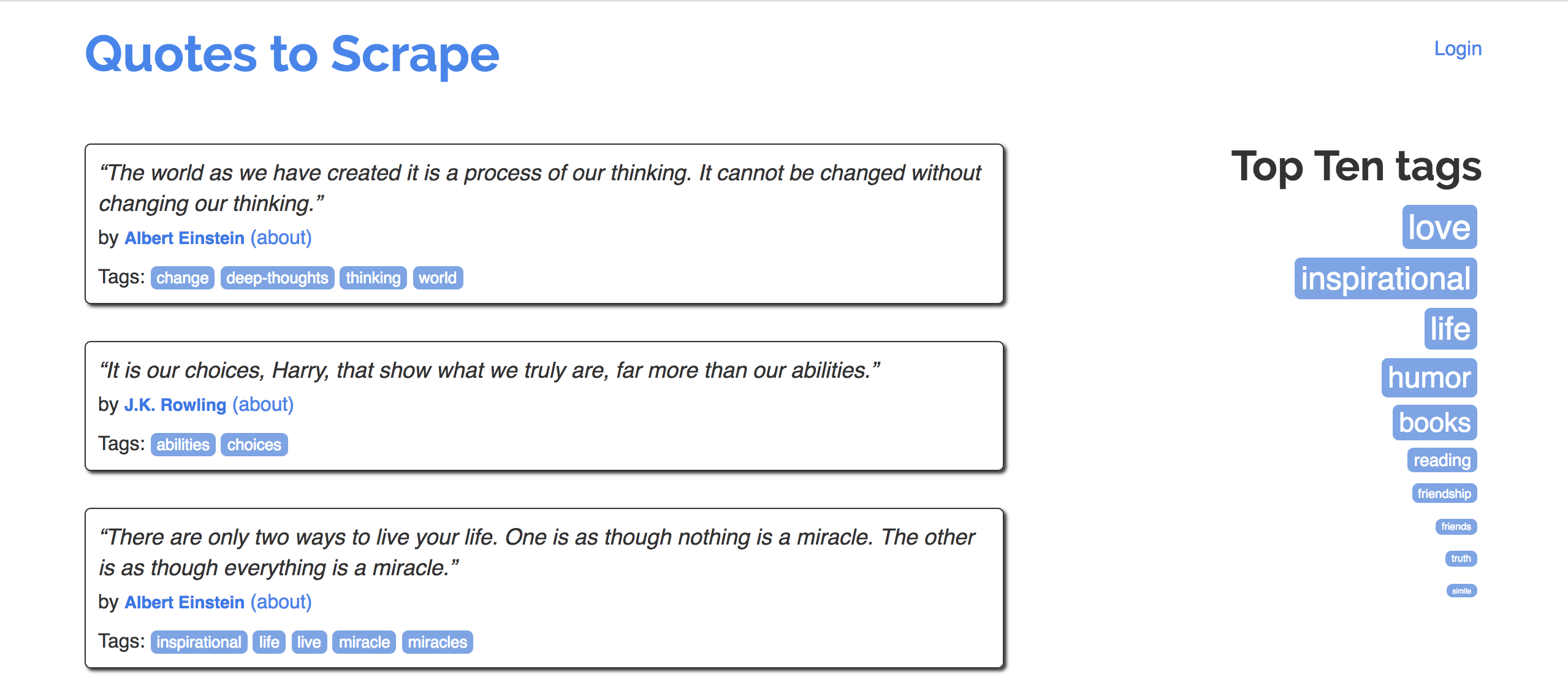
Specifically, let's try to make a DataFrame that looks like the one below:
| quote | author | author_url | tags | |
|---|---|---|---|---|
| 0 | “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” | Albert Einstein | https://quotes.toscrape.com/author/Albert-Einstein | change,deep-thoughts,thinking,world |
| 1 | “It is our choices, Harry, that show what we truly are, far more than our abilities.” | J.K. Rowling | https://quotes.toscrape.com/author/J-K-Rowling | abilities,choices |
| 2 | “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” | Albert Einstein | https://quotes.toscrape.com/author/Albert-Einstein | inspirational,life,live,miracle,miracles |
Eventually, we will create a single function – quote_df – which takes in an integer n and returns a DataFrame with the quotes on the first n pages of https://quotes.toscrape.com/.
To do this, we will define several helper functions:
download_page(i), which downloads a single page (page i) and returns a BeautifulSoup object of the response.process_quote(div), which takes in a <div> tree corresponding to a single quote and returns a Series containing all of the relevant information for that quote.process_page(divs), which takes in a list of <div> trees corresponding to a single page and returns a DataFrame containing all of the relevant information for all quotes on that page.Key principle: some of our helper functions will make requests, and others will parse, but none will do both!
def download_page(i):
url = f'https://quotes.toscrape.com/page/{i}'
request = requests.get(url)
return bs4.BeautifulSoup(request.text)
In quote_df, we will call download_page repeatedly – once for i=1, once for i=2, ..., i = n. For now, we will work with just page 5 (chosen arbitrarily).
soup = download_page(5)
Let's look at the page's source code (via "inspect element") to find where the quotes in the page are located.
divs = soup.find_all('div', attrs={'class': 'quote'})
divs[0]
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“A reader lives a thousand lives before he dies, said Jojen. The man who never reads lives only one.”</span>
<span>by <small class="author" itemprop="author">George R.R. Martin</small>
<a href="/author/George-R-R-Martin">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" content="read,readers,reading,reading-books" itemprop="keywords"/>
<a class="tag" href="/tag/read/page/1/">read</a>
<a class="tag" href="/tag/readers/page/1/">readers</a>
<a class="tag" href="/tag/reading/page/1/">reading</a>
<a class="tag" href="/tag/reading-books/page/1/">reading-books</a>
</div>
</div>
From this <div>, we can extract the quote, author name, author's URL, and tags.
divs[0].find('span', attrs={'class': 'text'}).text
'“A reader lives a thousand lives before he dies, said Jojen. The man who never reads lives only one.”'
divs[0].find('small', attrs={'class': 'author'}).text
'George R.R. Martin'
divs[0].find('a').get('href')
'/author/George-R-R-Martin'
divs[0].find('meta', attrs={'class': 'keywords'}).get('content')
'read,readers,reading,reading-books'
Let's implement our next function, process_quote, which takes in a <div> corresponding to a single quote and returns a Series containing the quote's information.
Note that this approach is different than the approach taken in the HDSI Faculty page example – there, we created each column of our final DataFrame separately, while here we are creating one row of our final DataFrame at a time.
def process_quote(div):
quote = div.find('span', attrs={'class': 'text'}).text
author = div.find('small', attrs={'class': 'author'}).text
author_url = 'https://quotes.toscrape.com' + div.find('a').get('href')
tags = div.find('meta', attrs={'class': 'keywords'}).get('content')
return pd.Series({'quote': quote, 'author': author, 'author_url': author_url, 'tags': tags})
process_quote(divs[3])
quote “If you can make a woman laugh, you can make h... author Marilyn Monroe author_url https://quotes.toscrape.com/author/Marilyn-Monroe tags girls,love dtype: object
Our last helper function will take in a list of <div>s, call process_quote on each <div> in the list, and return a DataFrame.
def process_page(divs):
return pd.DataFrame([process_quote(div) for div in divs])
process_page(divs)
| quote | author | author_url | tags | |
|---|---|---|---|---|
| 0 | “A reader lives a thousand lives before he die... | George R.R. Martin | https://quotes.toscrape.com/author/George-R-R-... | read,readers,reading,reading-books |
| 1 | “You can never get a cup of tea large enough o... | C.S. Lewis | https://quotes.toscrape.com/author/C-S-Lewis | books,inspirational,reading,tea |
| 2 | “You believe lies so you eventually learn to t... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe | |
| 3 | “If you can make a woman laugh, you can make h... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe | girls,love |
| 4 | “Life is like riding a bicycle. To keep your b... | Albert Einstein | https://quotes.toscrape.com/author/Albert-Eins... | life,simile |
| 5 | “The real lover is the man who can thrill you ... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe | love |
| 6 | “A wise girl kisses but doesn't love, listens ... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe | attributed-no-source |
| 7 | “Only in the darkness can you see the stars.” | Martin Luther King Jr. | https://quotes.toscrape.com/author/Martin-Luth... | hope,inspirational |
| 8 | “It matters not what someone is born, but what... | J.K. Rowling | https://quotes.toscrape.com/author/J-K-Rowling | dumbledore |
| 9 | “Love does not begin and end the way we seem t... | James Baldwin | https://quotes.toscrape.com/author/James-Baldwin | love |
def quote_df(n):
'''Returns a DataFrame containing the quotes on the first n pages of https://quotes.toscrape.com/.'''
dfs = []
for i in range(1, n + 1):
# Download page n and create a BeautifulSoup object.
soup = download_page(i)
# Create DataFrame using the information in that page.
divs = soup.find_all('div', attrs={'class': 'quote'})
df = process_page(divs)
# Append DataFrame to dfs.
dfs.append(df)
# Stitch all DataFrames together.
return pd.concat(dfs).reset_index(drop=True)
first_three_pages = quote_df(3)
first_three_pages.head()
| quote | author | author_url | tags | |
|---|---|---|---|---|
| 0 | “The world as we have created it is a process ... | Albert Einstein | https://quotes.toscrape.com/author/Albert-Eins... | change,deep-thoughts,thinking,world |
| 1 | “It is our choices, Harry, that show what we t... | J.K. Rowling | https://quotes.toscrape.com/author/J-K-Rowling | abilities,choices |
| 2 | “There are only two ways to live your life. On... | Albert Einstein | https://quotes.toscrape.com/author/Albert-Eins... | inspirational,life,live,miracle,miracles |
| 3 | “The person, be it gentleman or lady, who has ... | Jane Austen | https://quotes.toscrape.com/author/Jane-Austen | aliteracy,books,classic,humor |
| 4 | “Imperfection is beauty, madness is genius and... | Marilyn Monroe | https://quotes.toscrape.com/author/Marilyn-Monroe | be-yourself,inspirational |
The elements in the 'tags' column are all strings, but they look like lists. This is not ideal, as we will see shortly.
Nested data formats, like HTML, JSON, and XML, allow us to represent hierarchical relationships between variables.
Flat (i.e. tabular) data formats, like CSV, do not.
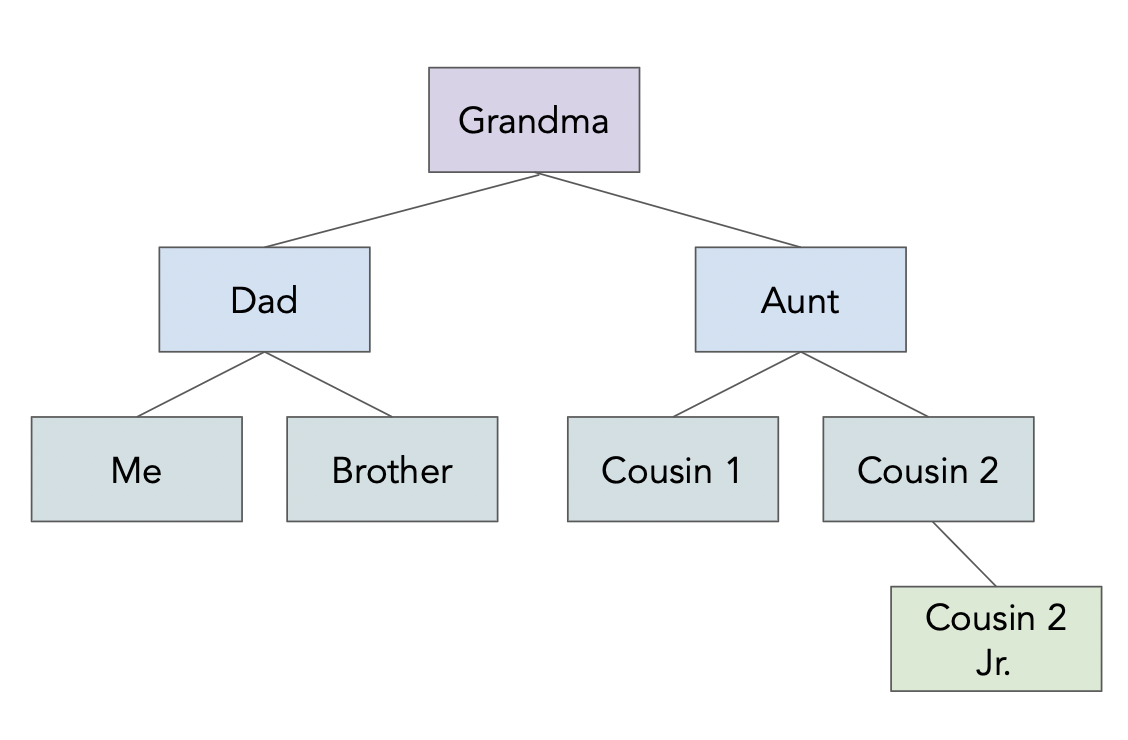
The site jsoncrack.com allows you to upload a JSON file and visualizes it. Let's try it with data/family.json!
data/quotes2scrape.json.quotes2scrape.json is a JSON records file; each line is a valid JSON object, but the entire document is not.f = open(os.path.join('data', 'quotes2scrape.json'))
json.loads(f.readline())
{'auth_url': 'http://quotes.toscrape.com/author/Albert-Einstein',
'quote_auth': 'Albert Einstein',
'quote_text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'bio': 'In 1879, Albert Einstein was born in Ulm, Germany. He completed his Ph.D. at the University of Zurich by 1909. His 1905 paper explaining the photoelectric effect, the basis of electronics, earned him the Nobel Prize in 1921. His first paper on Special Relativity Theory, also published in 1905, changed the world. After the rise of the Nazi party, Einstein made Princeton his permanent home, becoming a U.S. citizen in 1940. Einstein, a pacifist during World War I, stayed a firm proponent of social justice and responsibility. He chaired the Emergency Committee of Atomic Scientists, which organized to alert the public to the dangers of atomic warfare.At a symposium, he advised: "In their struggle for the ethical good, teachers of religion must have the stature to give up the doctrine of a personal God, that is, give up that source of fear and hope which in the past placed such vast power in the hands of priests. In their labors they will have to avail themselves of those forces which are capable of cultivating the Good, the True, and the Beautiful in humanity itself. This is, to be sure a more difficult but an incomparably more worthy task . . . " ("Science, Philosophy and Religion, A Symposium," published by the Conference on Science, Philosophy and Religion in their Relation to the Democratic Way of Life, Inc., New York, 1941). In a letter to philosopher Eric Gutkind, dated Jan. 3, 1954, Einstein stated: "The word god is for me nothing more than the expression and product of human weaknesses, the Bible a collection of honorable, but still primitive legends which are nevertheless pretty childish. No interpretation no matter how subtle can (for me) change this," (The Guardian, "Childish superstition: Einstein\'s letter makes view of religion relatively clear," by James Randerson, May 13, 2008). D. 1955.While best known for his mass–energy equivalence formula E = mc2 (which has been dubbed "the world\'s most famous equation"), he received the 1921 Nobel Prize in Physics "for his services to theoretical physics, and especially for his discovery of the law of the photoelectric effect". The latter was pivotal in establishing quantum theory.Einstein thought that Newtonion mechanics was no longer enough to reconcile the laws of classical mechanics with the laws of the electromagnetic field. This led to the development of his special theory of relativity. He realized, however, that the principle of relativity could also be extended to gravitational fields, and with his subsequent theory of gravitation in 1916, he published a paper on the general theory of relativity. He continued to deal with problems of statistical mechanics and quantum theory, which led to his explanations of particle theory and the motion of molecules. He also investigated the thermal properties of light which laid the foundation of the photon theory of light.He was visiting the United States when Adolf Hitler came to power in 1933 and did not go back to Germany. On the eve of World War II, he endorsed a letter to President Franklin D. Roosevelt alerting him to the potential development of "extremely powerful bombs of a new type" and recommending that the U.S. begin similar research. This eventually led to what would become the Manhattan Project. Einstein supported defending the Allied forces, but largely denounced the idea of using the newly discovered nuclear fission as a weapon. Later, with Bertrand Russell, Einstein signed the Russell–Einstein Manifesto, which highlighted the danger of nuclear weapons. Einstein was affiliated with the Institute for Advanced Study in Princeton, New Jersey, until his death in 1955.His great intellectual achievements and originality have made the word "Einstein" synonymous with genius.More: http://en.wikipedia.org/wiki/Albert_E...http://www.nobelprize.org/nobel_prize...',
'dob': 'March 14, 1879',
'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
Note that for a single quote, we have keys for 'auth_url', 'quote_auth', 'quote_text', 'bio', 'dob', and 'tags'.
Since each line is a separate JSON object, let's read in each line one at a time.
L = [json.loads(x) for x in open(os.path.join('data', 'quotes2scrape.json'))]
Let's convert the result to a DataFrame.
df = pd.DataFrame(L)
df.head()
| auth_url | quote_auth | quote_text | bio | dob | tags | |
|---|---|---|---|---|---|---|
| 0 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “The world as we have created it is a process ... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | [change, deep-thoughts, thinking, world] |
| 1 | http://quotes.toscrape.com/author/J-K-Rowling | J.K. Rowling | “It is our choices, Harry, that show what we t... | See also: Robert GalbraithAlthough she writes ... | July 31, 1965 | [abilities, choices] |
| 2 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “There are only two ways to live your life. On... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | [inspirational, life, live, miracle, miracles] |
| 3 | http://quotes.toscrape.com/author/Jane-Austen | Jane Austen | “The person, be it gentleman or lady, who has ... | Jane Austen was an English novelist whose work... | December 16, 1775 | [aliteracy, books, classic, humor] |
| 4 | http://quotes.toscrape.com/author/Marilyn-Monroe | Marilyn Monroe | “Imperfection is beauty, madness is genius and... | Marilyn Monroe (born Norma Jeane Mortenson; Ju... | June 01, 1926 | [be-yourself, inspirational] |
What data type is the 'tags' column?
df['tags'].iloc[0]
['change', 'deep-thoughts', 'thinking', 'world']
Let's save df to a CSV and read it back in.
df.to_csv('out.csv')
df_again = pd.read_csv('out.csv')
df_again.head()
| Unnamed: 0 | auth_url | quote_auth | quote_text | bio | dob | tags | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “The world as we have created it is a process ... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | ['change', 'deep-thoughts', 'thinking', 'world'] |
| 1 | 1 | http://quotes.toscrape.com/author/J-K-Rowling | J.K. Rowling | “It is our choices, Harry, that show what we t... | See also: Robert GalbraithAlthough she writes ... | July 31, 1965 | ['abilities', 'choices'] |
| 2 | 2 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “There are only two ways to live your life. On... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | ['inspirational', 'life', 'live', 'miracle', '... |
| 3 | 3 | http://quotes.toscrape.com/author/Jane-Austen | Jane Austen | “The person, be it gentleman or lady, who has ... | Jane Austen was an English novelist whose work... | December 16, 1775 | ['aliteracy', 'books', 'classic', 'humor'] |
| 4 | 4 | http://quotes.toscrape.com/author/Marilyn-Monroe | Marilyn Monroe | “Imperfection is beauty, madness is genius and... | Marilyn Monroe (born Norma Jeane Mortenson; Ju... | June 01, 1926 | ['be-yourself', 'inspirational'] |
What data type is the 'tags' column now?
df_again['tags'].iloc[0]
"['change', 'deep-thoughts', 'thinking', 'world']"
'inspirational'.'inspirational' column, it was tagged 'inspirational'.'inspirational' column, it was not tagged 'inspirational'.Let's write a function that takes in the list of tags (taglist) for a given quote and returns the one-hot-encoded sequence of 1s and 0s for that quote.
taglist
--------------------------------------------------------------------------- NameError Traceback (most recent call last) Input In [51], in <cell line: 1>() ----> 1 taglist NameError: name 'taglist' is not defined
def flatten_tags(taglist):
return pd.Series({k:1 for k in taglist}, dtype=float)
tags = df['tags'].apply(flatten_tags).fillna(0).astype(int)
tags.head()
| change | deep-thoughts | thinking | world | abilities | choices | inspirational | life | live | miracle | ... | christianity | faith | sun | adventure | better-life-empathy | difficult | grown-ups | write | writers | mind | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 137 columns
Let's combine this one-hot-encoded DataFrame with df.
df_full = pd.concat([df, tags], axis=1).drop(columns='tags')
df_full.head()
| auth_url | quote_auth | quote_text | bio | dob | change | deep-thoughts | thinking | world | abilities | ... | christianity | faith | sun | adventure | better-life-empathy | difficult | grown-ups | write | writers | mind | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “The world as we have created it is a process ... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | 1 | 1 | 1 | 1 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | http://quotes.toscrape.com/author/J-K-Rowling | J.K. Rowling | “It is our choices, Harry, that show what we t... | See also: Robert GalbraithAlthough she writes ... | July 31, 1965 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “There are only two ways to live your life. On... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | http://quotes.toscrape.com/author/Jane-Austen | Jane Austen | “The person, be it gentleman or lady, who has ... | Jane Austen was an English novelist whose work... | December 16, 1775 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | http://quotes.toscrape.com/author/Marilyn-Monroe | Marilyn Monroe | “Imperfection is beauty, madness is genius and... | Marilyn Monroe (born Norma Jeane Mortenson; Ju... | June 01, 1926 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 142 columns
If we want all quotes tagged 'inspiration', we can simply query:
df_full[df_full['inspirational'] == 1].head()
| auth_url | quote_auth | quote_text | bio | dob | change | deep-thoughts | thinking | world | abilities | ... | christianity | faith | sun | adventure | better-life-empathy | difficult | grown-ups | write | writers | mind | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | http://quotes.toscrape.com/author/Albert-Einstein | Albert Einstein | “There are only two ways to live your life. On... | In 1879, Albert Einstein was born in Ulm, Germ... | March 14, 1879 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | http://quotes.toscrape.com/author/Marilyn-Monroe | Marilyn Monroe | “Imperfection is beauty, madness is genius and... | Marilyn Monroe (born Norma Jeane Mortenson; Ju... | June 01, 1926 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 7 | http://quotes.toscrape.com/author/Thomas-A-Edison | Thomas A. Edison | “I have not failed. I've just found 10,000 way... | Thomas Alva Edison was an American inventor, s... | February 11, 1847 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | http://quotes.toscrape.com/author/Marilyn-Monroe | Marilyn Monroe | “This life is what you make it. No matter what... | Marilyn Monroe (born Norma Jeane Mortenson; Ju... | June 01, 1926 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | http://quotes.toscrape.com/author/Elie-Wiesel | Elie Wiesel | “The opposite of love is not hate, it's indiff... | Eliezer Wiesel was a Romania-born American nov... | September 30, 1928 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 142 columns
Note that this DataFrame representation of the response JSON takes up much more space than the original JSON. Why is that?
soup.find and soup.find_all are the functions you will use most often.All about regular expressions!