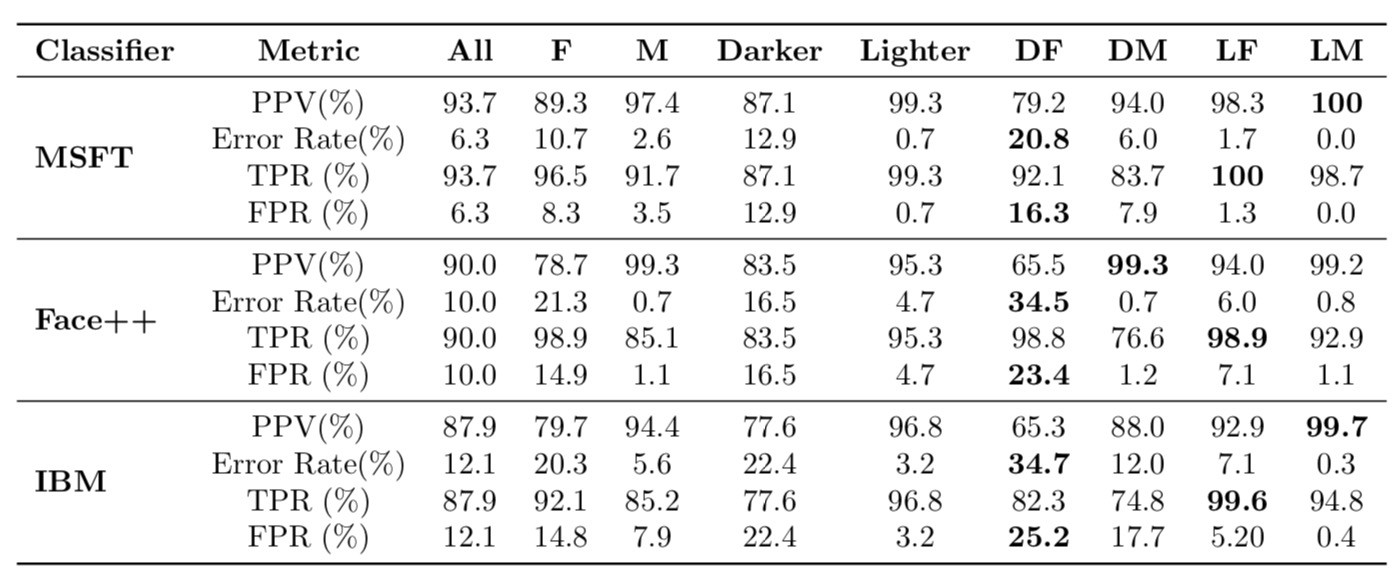
Example: COMPAS and recidivism prediction¶
COMPAS (Correctional Offender Management Profiling for Alternative Sanctions) is a "black-box" model that estimates the likelihood that someone who has commited a crime will recidivate (commit another crime).
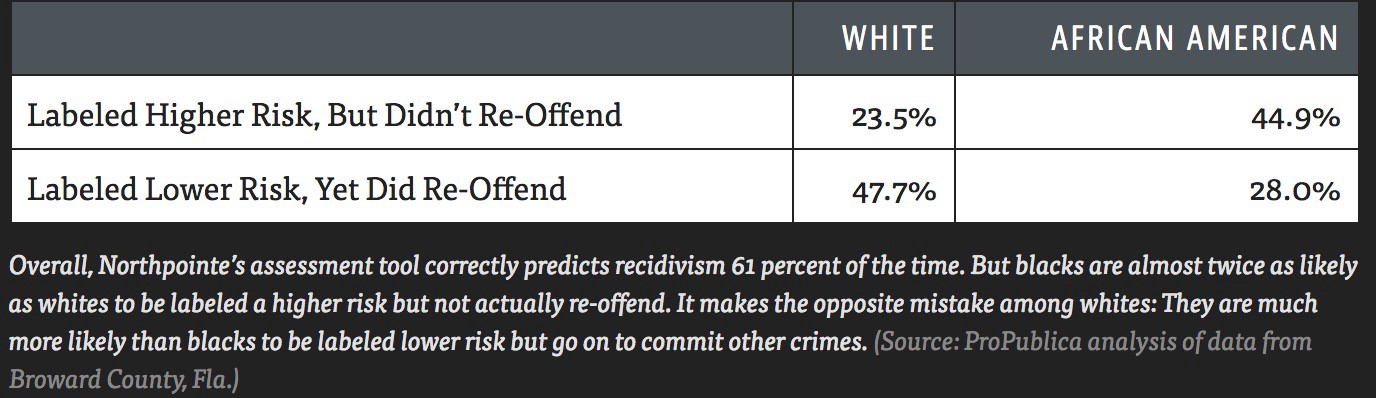
Propublica found that the model's false positive rate is higher for African-Americans than it is for White Americans, and that its false negative rate is lower for African-Americans than it is for White Americans.