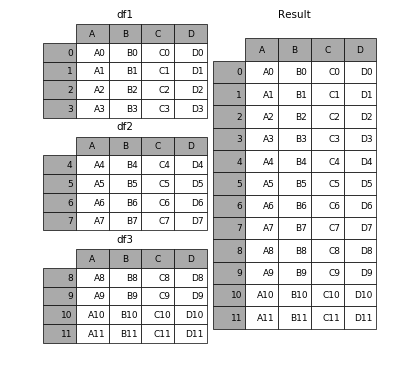
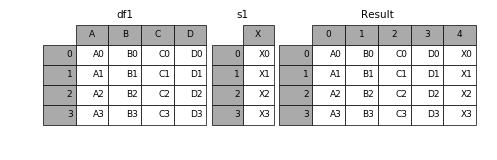
# Run this cell to set up the next example.
profs = pd.DataFrame(
[['Brad', 'UCB', 9],
['Janine', 'UCSD', 8],
['Marina', 'UIC', 7],
['Justin', 'OSU', 5],
['Soohyun', 'UCSD', 2],
['Suraj', 'UCB', 2]],
columns=['Name', 'School', 'Years']
)
schools = pd.DataFrame({
'Abr': ['UCSD', 'UCLA', 'UCB', 'UIC'],
'Full': ['University of California, San Diego', 'University of California, Los Angeles', 'University of California, Berkeley', 'University of Illinois Chicago']
})
programs = pd.DataFrame({
'uni': ['UCSD', 'UCSD', 'UCSD', 'UCB', 'OSU', 'OSU'],
'dept': ['Math', 'HDSI', 'COGS', 'CS', 'Math', 'CS'],
'grad_students': [205, 54, 281, 439, 304, 193]
})