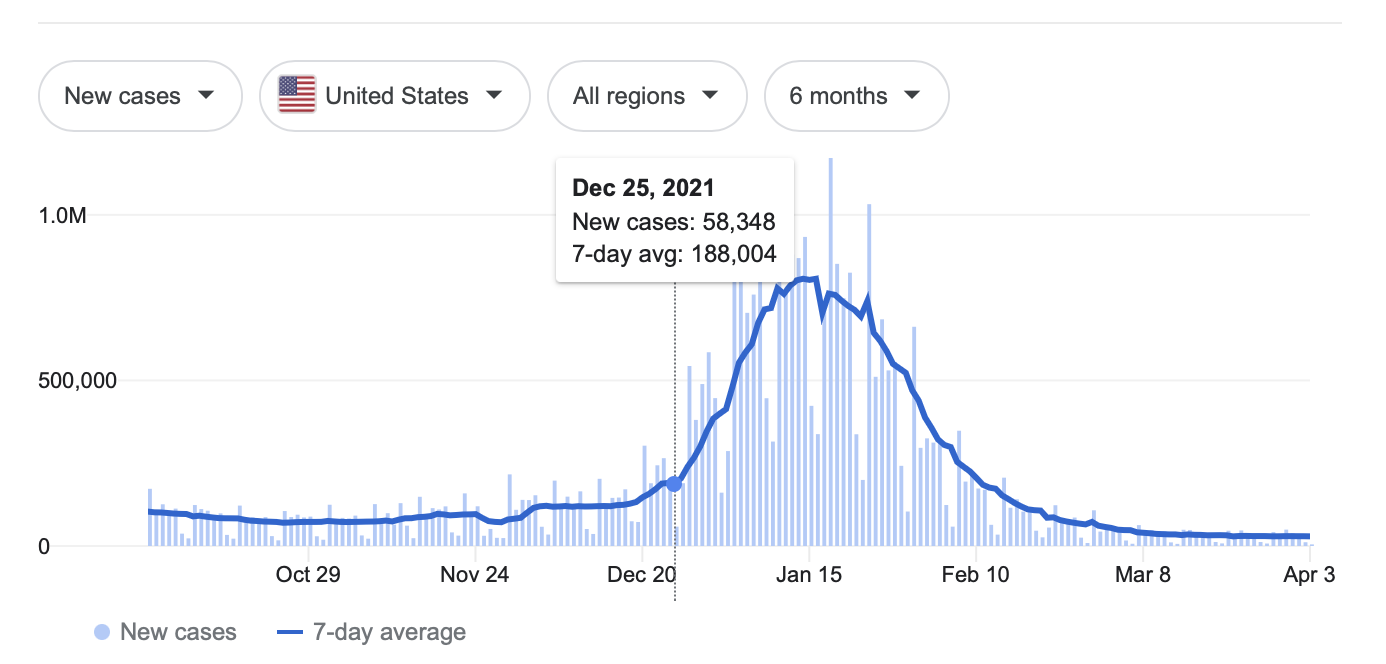
Why do you think so few cases were reported on Christmas Day – is it because COVID was less prevalent on Christmas Day as compared to the days before and after, or is it likely for some other reason? 🎅
import pandas as pd
import numpy as np
import os
For illustration purposes, let's look at the temperatures and countries example DataFrames from the last lecture, with slight modifications.
temps = pd.DataFrame({
'City': ['San Diego', 'Toronto', 'Rome'],
'Temperature': [76, 28, 56],
'Humid': ['No', 'Yes', 'Yes']
})
other_temps = pd.DataFrame({
'City': ['Los Angeles', 'San Diego', 'Miami'],
'Temperature': [79, 76, 88],
'Humid': ['No', 'No', 'Yes']
})
countries = pd.DataFrame({
'City': ['Toronto', 'Shanghai', 'San Diego'],
'Country': ['Canada', 'China', 'USA']
})
temps
| City | Temperature | Humid | |
|---|---|---|---|
| 0 | San Diego | 76 | No |
| 1 | Toronto | 28 | Yes |
| 2 | Rome | 56 | Yes |
other_temps
| City | Temperature | Humid | |
|---|---|---|---|
| 0 | Los Angeles | 79 | No |
| 1 | San Diego | 76 | No |
| 2 | Miami | 88 | Yes |
countries
| City | Country | |
|---|---|---|
| 0 | Toronto | Canada |
| 1 | Shanghai | China |
| 2 | San Diego | USA |
Used to project (keep) columns in a relation. Duplicates rows are dropped.
$$\Pi_{(\text{City, Humid})}(\text{temps})$$temps[['City', 'Humid']].drop_duplicates()
| City | Humid | |
|---|---|---|
| 0 | San Diego | No |
| 1 | Toronto | Yes |
| 2 | Rome | Yes |
Used to keep rows in a relation that satisfy certain conditions.
$$\sigma_{(\text{Temperature} > 50)}(\text{temps})$$temps[temps['Temperature'] > 50]
| City | Temperature | Humid | |
|---|---|---|---|
| 0 | San Diego | 76 | No |
| 2 | Rome | 56 | Yes |
Operators can be composed:
$$\Pi_{(\text{City, Humid})} \big(\sigma_{(\text{Temperature} > 50)}(\text{temps}) \big)$$temps.loc[temps['Temperature'] > 50, ['City', 'Humid']].drop_duplicates()
| City | Humid | |
|---|---|---|
| 0 | San Diego | No |
| 2 | Rome | Yes |
Used to create every possible combination of rows in the first relation with rows in the second relation.
$$\text{temps} \times \text{countries}$$# Could also use temps.merge(countries, how='cross').
pd.merge(temps, countries, how='cross')
| City_x | Temperature | Humid | City_y | Country | |
|---|---|---|---|---|---|
| 0 | San Diego | 76 | No | Toronto | Canada |
| 1 | San Diego | 76 | No | Shanghai | China |
| 2 | San Diego | 76 | No | San Diego | USA |
| 3 | Toronto | 28 | Yes | Toronto | Canada |
| 4 | Toronto | 28 | Yes | Shanghai | China |
| 5 | Toronto | 28 | Yes | San Diego | USA |
| 6 | Rome | 56 | Yes | Toronto | Canada |
| 7 | Rome | 56 | Yes | Shanghai | China |
| 8 | Rome | 56 | Yes | San Diego | USA |
The cross product is not incredibly useful on its own, but it can be used with other operators to perform more meaningful operations.
What does the following compute?
$$\sigma_{\text{temps.City = countries.City}} \big( \text{temps} \times \text{countries} \big)$$both = pd.merge(temps, countries, how='cross')
both[both['City_x'] == both['City_y']]
| City_x | Temperature | Humid | City_y | Country | |
|---|---|---|---|---|---|
| 2 | San Diego | 76 | No | San Diego | USA |
| 3 | Toronto | 28 | Yes | Toronto | Canada |
temps.merge(countries)
| City | Temperature | Humid | Country | |
|---|---|---|---|---|
| 0 | San Diego | 76 | No | USA |
| 1 | Toronto | 28 | Yes | Canada |
Used to combine the rows of two relations. Duplicate rows are dropped. Only works if the two relations have the same attributes (column names).
pd.concat([temps, other_temps]).drop_duplicates()
| City | Temperature | Humid | |
|---|---|---|---|
| 0 | San Diego | 76 | No |
| 1 | Toronto | 28 | Yes |
| 2 | Rome | 56 | Yes |
| 0 | Los Angeles | 79 | No |
| 2 | Miami | 88 | Yes |
Used to find the rows that are in one relation but not the other. Only works if the two relations have the same attributes (column names).
$$\text{temps} - \text{other_temps}$$temps[~temps['City'].isin(other_temps['City'])]
| City | Temperature | Humid | |
|---|---|---|---|
| 1 | Toronto | 28 | Yes |
| 2 | Rome | 56 | Yes |
otter cases.Suppose our goal is to determine the number of COVID cases in the US yesterday.
Why do you think so few cases were reported on Christmas Day – is it because COVID was less prevalent on Christmas Day as compared to the days before and after, or is it likely for some other reason? 🎅
The bigger picture question we're asking here is, can we trust our data?
Data cleaning is the process of transforming data so that it best represents the underlying data generating process.
In practice, data cleaning is often detective work to understand data provenance.
Data cleaning often addresses:
Let's focus on the latter two.

Determine the kind of each of the following variables.
In the next cell, we'll load in an example dataset containing information about past DSC 80 students.
'PID' and 'Student Name': student PID and name.'Month', 'Day', 'Year': date when the student was accepted to UCSD.'2021 tuition' and '2022 tuition': amount paid in tuition in 2021 and 2022, respectively.'Percent Growth': growth between the two aforementioned columns.'Paid': whether or not the student has paid tuition for this quarter yet.'DSC 80 Final Grade': either 'Pass', 'Fail', or a number.What needs to be changed in the DataFrame to extract meaningful insights?
students = pd.read_csv(os.path.join('data', 'students.csv'))
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | $40000.00 | $50000.00 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | $9200.00 | $10120.00 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | $50000.00 | $62500.00 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | $7000.00 | $9800.00 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | $10000.00 | $5000.00 | -50.00% | Y | Pass |
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | $40000.00 | $50000.00 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | $9200.00 | $10120.00 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | $50000.00 | $62500.00 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | $7000.00 | $9800.00 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | $10000.00 | $5000.00 | -50.00% | Y | Pass |
total = students['2021 tuition'] + students['2022 tuition']
total
0 $40000.00$50000.00 1 $9200.00$10120.00 2 $50000.00$62500.00 3 $7000.00$9800.00 4 $10000.00$5000.00 dtype: object
students!¶What data type should each column have?
Use the dtypes attribute or the info method to peek at the data types.
students.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 5 entries, 0 to 4 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Student ID 5 non-null object 1 Student Name 5 non-null object 2 Month 5 non-null int64 3 Day 5 non-null int64 4 Year 5 non-null int64 5 2021 tuition 5 non-null object 6 2022 tuition 5 non-null object 7 Percent Growth 5 non-null object 8 Paid 5 non-null object 9 DSC 80 Final Grade 5 non-null object dtypes: int64(3), object(7) memory usage: 528.0+ bytes
'2021 tuition' and '2022 tuition'¶'2021 tuition' and '2022 tuition' are stored as objects (strings), not numerical values.'$' character causes the entries to be interpreted as strings.str methods to strip the dollar sign..str will be applied to each element of the Series individually, rather than the Series as a whole.# This won't work. Why?
students['2021 tuition'].astype(float)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_68707/2133079742.py in <module> 1 # This won't work. Why? ----> 2 students['2021 tuition'].astype(float) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/generic.py in astype(self, dtype, copy, errors) 6238 else: 6239 # else, only a single dtype is given -> 6240 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors) 6241 return self._constructor(new_data).__finalize__(self, method="astype") 6242 ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in astype(self, dtype, copy, errors) 443 444 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T: --> 445 return self.apply("astype", dtype=dtype, copy=copy, errors=errors) 446 447 def convert( ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 345 applied = b.apply(f, **kwargs) 346 else: --> 347 applied = getattr(b, f)(**kwargs) 348 except (TypeError, NotImplementedError): 349 if not ignore_failures: ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/blocks.py in astype(self, dtype, copy, errors) 524 values = self.values 525 --> 526 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors) 527 528 new_values = maybe_coerce_values(new_values) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_array_safe(values, dtype, copy, errors) 297 298 try: --> 299 new_values = astype_array(values, dtype, copy=copy) 300 except (ValueError, TypeError): 301 # e.g. astype_nansafe can fail on object-dtype of strings ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_array(values, dtype, copy) 228 229 else: --> 230 values = astype_nansafe(values, dtype, copy=copy) 231 232 # in pandas we don't store numpy str dtypes, so convert to object ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_nansafe(arr, dtype, copy, skipna) 168 if copy or is_object_dtype(arr.dtype) or is_object_dtype(dtype): 169 # Explicit copy, or required since NumPy can't view from / to object. --> 170 return arr.astype(dtype, copy=True) 171 172 return arr.astype(dtype, copy=copy) ValueError: could not convert string to float: '$40000.00'
# That's better!
students['2021 tuition'].str.strip('$').astype(float)
0 40000.0 1 9200.0 2 50000.0 3 7000.0 4 10000.0 Name: 2021 tuition, dtype: float64
We can loop through the columns of students to apply the above procedure. (Looping through columns is fine, just avoid looping through rows.)
for col in students.columns:
if 'tuition' in col:
students[col] = students[col].str.strip('$').astype(float)
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | Y | Pass |
Alternatively, we can do this without a loop by using str.contains to find only the columns that contain tuition information.
cols = students.columns.str.contains('tuition')
students.loc[:, cols] = students.loc[:, cols].astype(float)
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | N | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | Y | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | N | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | Y | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | Y | Pass |
'Paid'¶'Paid' contains the strings 'Y' and 'N'.'Y's and 'N's typically result from manual data entry.'Paid' column should contain Trues and Falses, or 1s and 0s.replace method.students['Paid'].value_counts()
Y 3 N 2 Name: Paid, dtype: int64
students['Paid'] = students['Paid'] == 'Y'
students
| Student ID | Student Name | Month | Day | Year | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 10 | 12 | 2020 | 40000.0 | 50000.0 | 25.00% | False | 89 |
| 1 | A20345992 | Mark White | 4 | 15 | 2019 | 9200.0 | 10120.0 | 10.00% | True | 90 |
| 2 | A21942188 | Amy Red | 5 | 14 | 2021 | 50000.0 | 62500.0 | 25.00% | False | 97 |
| 3 | A28049910 | Tom Green | 7 | 10 | 2020 | 7000.0 | 9800.0 | 40.00% | True | 54 |
| 4 | A27456704 | Rose Pink | 3 | 3 | 2021 | 10000.0 | 5000.0 | -50.00% | True | Pass |
'Month', 'Day', and 'Year'¶int64 data type. This could be fine for certain purposes, but ideally they are stored as a single column (e.g. for sorting).pd.to_datetime to convert dates to datetime64 objects.students.loc[:, 'Month': 'Year']
| Month | Day | Year | |
|---|---|---|---|
| 0 | 10 | 12 | 2020 |
| 1 | 4 | 15 | 2019 |
| 2 | 5 | 14 | 2021 |
| 3 | 7 | 10 | 2020 |
| 4 | 3 | 3 | 2021 |
students['Date'] = pd.to_datetime(students.loc[:, 'Month': 'Year'])
students = students.drop(columns=['Month', 'Day', 'Year'])
students
| Student ID | Student Name | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | Date | |
|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 40000.0 | 50000.0 | 25.00% | False | 89 | 2020-10-12 |
| 1 | A20345992 | Mark White | 9200.0 | 10120.0 | 10.00% | True | 90 | 2019-04-15 |
| 2 | A21942188 | Amy Red | 50000.0 | 62500.0 | 25.00% | False | 97 | 2021-05-14 |
| 3 | A28049910 | Tom Green | 7000.0 | 9800.0 | 40.00% | True | 54 | 2020-07-10 |
| 4 | A27456704 | Rose Pink | 10000.0 | 5000.0 | -50.00% | True | Pass | 2021-03-03 |
'DSC 80 Final Grade'¶'DSC 80 Final Grade's are stored as objects (strings).'Pass', we can't use astype to convert it.pd.to_numeric(s, errors='coerce'), where s is a Series.errors='coerce' can cause uninformed destruction of data.# Won't work!
students['DSC 80 Final Grade'].astype(int)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_68707/1326609327.py in <module> 1 # Won't work! ----> 2 students['DSC 80 Final Grade'].astype(int) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/generic.py in astype(self, dtype, copy, errors) 6238 else: 6239 # else, only a single dtype is given -> 6240 new_data = self._mgr.astype(dtype=dtype, copy=copy, errors=errors) 6241 return self._constructor(new_data).__finalize__(self, method="astype") 6242 ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in astype(self, dtype, copy, errors) 443 444 def astype(self: T, dtype, copy: bool = False, errors: str = "raise") -> T: --> 445 return self.apply("astype", dtype=dtype, copy=copy, errors=errors) 446 447 def convert( ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/managers.py in apply(self, f, align_keys, ignore_failures, **kwargs) 345 applied = b.apply(f, **kwargs) 346 else: --> 347 applied = getattr(b, f)(**kwargs) 348 except (TypeError, NotImplementedError): 349 if not ignore_failures: ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/internals/blocks.py in astype(self, dtype, copy, errors) 524 values = self.values 525 --> 526 new_values = astype_array_safe(values, dtype, copy=copy, errors=errors) 527 528 new_values = maybe_coerce_values(new_values) ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_array_safe(values, dtype, copy, errors) 297 298 try: --> 299 new_values = astype_array(values, dtype, copy=copy) 300 except (ValueError, TypeError): 301 # e.g. astype_nansafe can fail on object-dtype of strings ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_array(values, dtype, copy) 228 229 else: --> 230 values = astype_nansafe(values, dtype, copy=copy) 231 232 # in pandas we don't store numpy str dtypes, so convert to object ~/opt/anaconda3/lib/python3.9/site-packages/pandas/core/dtypes/astype.py in astype_nansafe(arr, dtype, copy, skipna) 168 if copy or is_object_dtype(arr.dtype) or is_object_dtype(dtype): 169 # Explicit copy, or required since NumPy can't view from / to object. --> 170 return arr.astype(dtype, copy=True) 171 172 return arr.astype(dtype, copy=copy) ValueError: invalid literal for int() with base 10: 'Pass'
pd.to_numeric(students['DSC 80 Final Grade'], errors='coerce')
0 89.0 1 90.0 2 97.0 3 54.0 4 NaN Name: DSC 80 Final Grade, dtype: float64
students['DSC 80 Final Grade'] = pd.to_numeric(students['DSC 80 Final Grade'], errors='coerce')
students
| Student ID | Student Name | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | Date | |
|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | John Black | 40000.0 | 50000.0 | 25.00% | False | 89.0 | 2020-10-12 |
| 1 | A20345992 | Mark White | 9200.0 | 10120.0 | 10.00% | True | 90.0 | 2019-04-15 |
| 2 | A21942188 | Amy Red | 50000.0 | 62500.0 | 25.00% | False | 97.0 | 2021-05-14 |
| 3 | A28049910 | Tom Green | 7000.0 | 9800.0 | 40.00% | True | 54.0 | 2020-07-10 |
| 4 | A27456704 | Rose Pink | 10000.0 | 5000.0 | -50.00% | True | NaN | 2021-03-03 |
pd.to_numeric?
'Student Name'¶'Last Name, First Name', a common format.str methods once again.students['Student Name']
0 John Black 1 Mark White 2 Amy Red 3 Tom Green 4 Rose Pink Name: Student Name, dtype: object
parts = students['Student Name'].str.split()
parts
0 [John, Black] 1 [Mark, White] 2 [Amy, Red] 3 [Tom, Green] 4 [Rose, Pink] Name: Student Name, dtype: object
students['Student Name'] = parts.str[1] + ', ' + parts.str[0]
students
| Student ID | Student Name | 2021 tuition | 2022 tuition | Percent Growth | Paid | DSC 80 Final Grade | Date | |
|---|---|---|---|---|---|---|---|---|
| 0 | A20104523 | Black, John | 40000.0 | 50000.0 | 25.00% | False | 89.0 | 2020-10-12 |
| 1 | A20345992 | White, Mark | 9200.0 | 10120.0 | 10.00% | True | 90.0 | 2019-04-15 |
| 2 | A21942188 | Red, Amy | 50000.0 | 62500.0 | 25.00% | False | 97.0 | 2021-05-14 |
| 3 | A28049910 | Green, Tom | 7000.0 | 9800.0 | 40.00% | True | 54.0 | 2020-07-10 |
| 4 | A27456704 | Pink, Rose | 10000.0 | 5000.0 | -50.00% | True | NaN | 2021-03-03 |
1649043031 looks like a number, but is probably a date.
"USD 1,000,000" looks like a string, but is actually a number and a unit.
92093 looks like a number, but is really a zip code (and isn't equal to 92,093).
Sometimes, False appears in a column of country codes. Why might this be?
🤔
import yaml
player = '''
name: Magnus Carlsen
age: 32
country: NO
'''
yaml.safe_load(player)
{'name': 'Magnus Carlsen', 'age': 32, 'country': False}