Heading here
My First paragraph
My second paragraph
import pandas as pd
import numpy as np
import os
import requests
import util
Responses typically come in one of two formats: HTML or JSON.
GET request is usually either JSON (when using an API) or HTML (when accessing a webpage).POST request is usually JSON.| Type | Description |
|---|---|
| String | Anything inside double quotes. |
| Number | Any number (no difference between ints and floats). |
| Boolean | true and false. |
| Null | JSON's empty value, denoted by null. |
| Array | Like Python lists. |
| Object | A collection of key-value pairs, like dictionaries. Keys must be strings, values can be anything (even other objects). |
See json-schema.org for more details.
import json
f = open(os.path.join('data', 'family.json'), 'r')
family_tree = json.load(f)
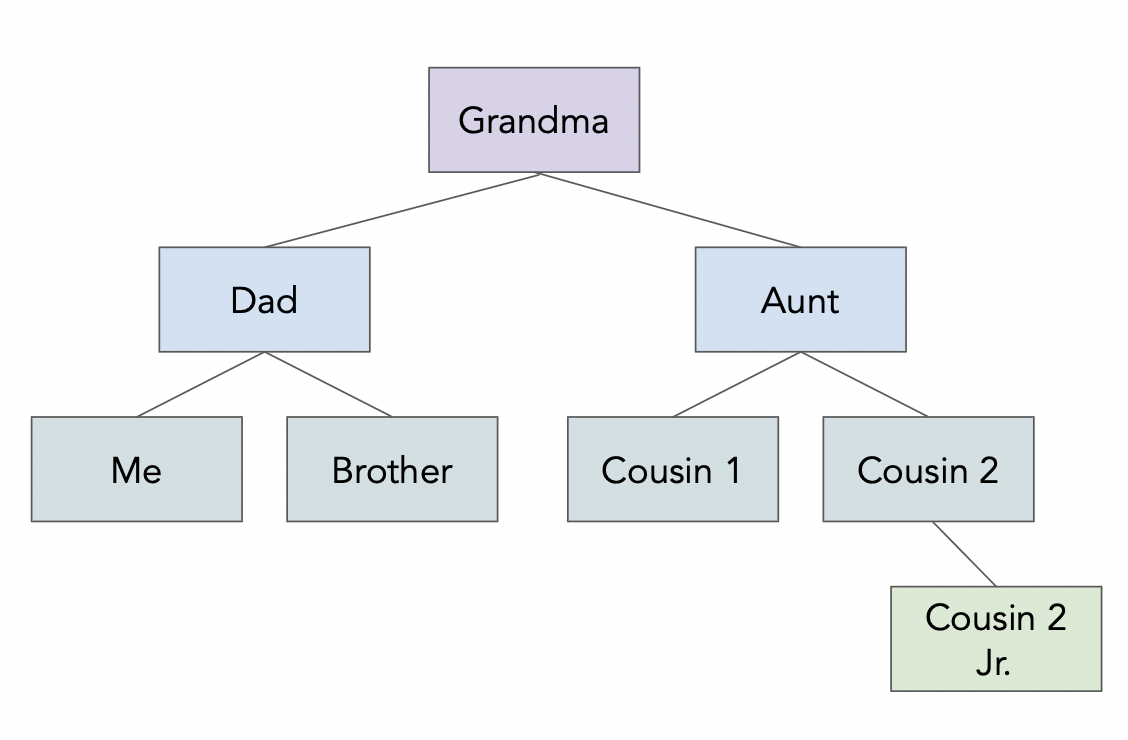
family_tree
{'name': 'Grandma',
'age': 94,
'children': [{'name': 'Dad',
'age': 60,
'children': [{'name': 'Me', 'age': 24}, {'name': 'Brother', 'age': 22}]},
{'name': 'My Aunt',
'children': [{'name': 'Cousin 1', 'age': 34},
{'name': 'Cousin 2',
'age': 36,
'children': [{'name': 'Cousin 2 Jr.', 'age': 2}]}]}]}
family_tree['children'][0]['children'][0]['age']
24
eval¶eval, which stands for "evaluate", is a function built into Python.x = 4
eval('x + 5')
9
eval can do the same thing that json.load does...f = open(os.path.join('data', 'family.json'), 'r')
eval(f.read())
{'name': 'Grandma',
'age': 94,
'children': [{'name': 'Dad',
'age': 60,
'children': [{'name': 'Me', 'age': 24}, {'name': 'Brother', 'age': 22}]},
{'name': 'My Aunt',
'children': [{'name': 'Cousin 1', 'age': 34},
{'name': 'Cousin 2',
'age': 36,
'children': [{'name': 'Cousin 2 Jr.', 'age': 2}]}]}]}
eval. The next slide demonstrates why.eval gone wrong¶Observe what happens when we use eval on a string representation of a JSON object:
f_other = open(os.path.join('data', 'evil_family.json'))
eval(f_other.read())
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_9416/3392341705.py in <module> 1 f_other = open(os.path.join('data', 'evil_family.json')) ----> 2 eval(f_other.read()) <string> in <module> ~/Desktop/80/wi23/private/lectures/schedules/mwf/lec15/src/util.py in err() 171 # For JSON evaluation example 172 def err(): --> 173 raise ValueError('i just deleted all your files lol 😂') ValueError: i just deleted all your files lol 😂
evil_family.json, which could have been downloaded from the internet, contained malicious code, we now lost all of our files.eval evaluates all parts of the input string as if it were Python code..json() method of a response object, or use the json library.json module¶Let's process the same file using the json module. Recall:
json.load(f) loads a JSON file from a file object.json.loads(f) loads a JSON file from a string.f_other = open(os.path.join('data', 'evil_family.json'))
s = f_other.read()
s
'{\n "name": "Grandma",\n "age": 94,\n "children": [\n {\n "name": util.err(),\n "age": 60,\n "children": [{"name": "Me", "age": 24}, \n {"name": "Brother", "age": 22}]\n },\n {\n "name": "My Aunt",\n "children": [{"name": "Cousin 1", "age": 34}, \n {"name": "Cousin 2", "age": 36, "children": \n [{"name": "Cousin 2 Jr.", "age": 2}]\n }\n ]\n }\n ]\n}'
json.loads(s)
--------------------------------------------------------------------------- JSONDecodeError Traceback (most recent call last) /var/folders/pd/w73mdrsj2836_7gp0brr2q7r0000gn/T/ipykernel_9416/1938830664.py in <module> ----> 1 json.loads(s) ~/opt/anaconda3/lib/python3.9/json/__init__.py in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw) 344 parse_int is None and parse_float is None and 345 parse_constant is None and object_pairs_hook is None and not kw): --> 346 return _default_decoder.decode(s) 347 if cls is None: 348 cls = JSONDecoder ~/opt/anaconda3/lib/python3.9/json/decoder.py in decode(self, s, _w) 335 336 """ --> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end()) 338 end = _w(s, end).end() 339 if end != len(s): ~/opt/anaconda3/lib/python3.9/json/decoder.py in raw_decode(self, s, idx) 353 obj, end = self.scan_once(s, idx) 354 except StopIteration as err: --> 355 raise JSONDecodeError("Expecting value", s, err.value) from None 356 return obj, end JSONDecodeError: Expecting value: line 6 column 17 (char 84)
util.err() is not a string in JSON (there are no quotes around it), json.loads is not able to parse it as a JSON object.eval on "raw" data that you didn't create!requests package to exchange data via HTTP.GET requests are used to request data from a server.POST requests are used to send data to a server.An API is a service that makes data directly available to the user in a convenient fashion.
Advantages:
Disadvantages:
A URL, or uniform resource locator, describes the location of a website or resource.
An API endpoint is a URL of the data source that the user wants to make requests to.
For example, on the Reddit API:
/comments endpoint retrieves information about comments./hot endpoint retrieves data about posts labeled "hot" right now. GET/POST requests to a specially maintained URL.First, let's make a GET request for 'squirtle'.
r = requests.get('https://pokeapi.co/api/v2/pokemon/squirtle')
r
<Response [200]>
Remember, the 200 status code is good! Let's take a look at the content:
r.content[:1000]
b'{"abilities":[{"ability":{"name":"torrent","url":"https://pokeapi.co/api/v2/ability/67/"},"is_hidden":false,"slot":1},{"ability":{"name":"rain-dish","url":"https://pokeapi.co/api/v2/ability/44/"},"is_hidden":true,"slot":3}],"base_experience":63,"forms":[{"name":"squirtle","url":"https://pokeapi.co/api/v2/pokemon-form/7/"}],"game_indices":[{"game_index":177,"version":{"name":"red","url":"https://pokeapi.co/api/v2/version/1/"}},{"game_index":177,"version":{"name":"blue","url":"https://pokeapi.co/api/v2/version/2/"}},{"game_index":177,"version":{"name":"yellow","url":"https://pokeapi.co/api/v2/version/3/"}},{"game_index":7,"version":{"name":"gold","url":"https://pokeapi.co/api/v2/version/4/"}},{"game_index":7,"version":{"name":"silver","url":"https://pokeapi.co/api/v2/version/5/"}},{"game_index":7,"version":{"name":"crystal","url":"https://pokeapi.co/api/v2/version/6/"}},{"game_index":7,"version":{"name":"ruby","url":"https://pokeapi.co/api/v2/version/7/"}},{"game_index":7,"version":{"nam'
Looks like JSON. We can extract the JSON from this request with the json method (or by passing r.text to json.loads).
r.json()
Let's try a GET request for 'billy'.
r = requests.get('https://pokeapi.co/api/v2/pokemon/billy')
r
<Response [404]>
Uh oh...
Scraping is the act of programmatically "browsing" the web, downloading the source code (HTML) of pages that you're interested in extracting data from.
Advantages:
Disadvantages:
Goal: Access information about HDSI faculty members from the HDSI Faculty page.
Let's start by making a GET request to the HDSI Faculty page and see what the resulting HTML looks like.
r = requests.get('https://datascience.ucsd.edu/about/faculty/faculty/')
r
<Response [200]>
faculty_text = r.text
len(faculty_text)
903197
print(faculty_text[:1000])
<!DOCTYPE html><html lang="en-US"><head><meta charset="UTF-8"><style media="all">img.wp-smiley,img.emoji{display:inline !important;border:none !important;box-shadow:none !important;height:1em !important;width:1em !important;margin:0 .07em !important;vertical-align:-.1em !important;background:0 0 !important;padding:0 !important}
/*!
* Font Awesome Free 6.1.2 by @fontawesome - https://fontawesome.com
* License - https://fontawesome.com/license/free (Icons: CC BY 4.0, Fonts: SIL OFL 1.1, Code: MIT License)
* Copyright 2022 Fonticons, Inc.
*/
.fa{font-family:var(--fa-style-family,"Font Awesome 6 Free");font-weight:var(--fa-style,900)}.fa,.fa-brands,.fa-duotone,.fa-light,.fa-regular,.fa-solid,.fa-thin,.fab,.fad,.fal,.far,.fas,.fat{-moz-osx-font-smoothing:grayscale;-webkit-font-smoothing:antialiased;display:var(--fa-display,inline-block);font-style:normal;font-variant:normal;line-height:1;text-rendering:auto}.fa-1x{font-size:1em}.fa-2x{font-size:2em}.fa-3x{font-size:3em}.fa-4x{font-size:
'Suraj Rampure' in faculty_text
True
Wow, that is gross looking! 😰
robots.txt file.robots.txt file in their root directory, which contains a policy that allows or disallows automatic access to their site. If you make too many requests:
For instance, here's the content of a very basic webpage.
!cat data/lec15_ex1.html
<html> <head> <title>Page title</title> </head> <body> <h1>This is a heading</h1> <p>This is a paragraph.</p> <p>This is <b>another</b> paragraph.</p> </body> </html>
Using IPython.display.HTML, we can render it directly in our notebook.
from IPython.display import HTML
HTML(os.path.join('data', 'lec15_ex1.html'))
This is a paragraph.
This is another paragraph.
HTML document: The totality of markup that makes up a webpage.
Document Object Model (DOM): The internal representation of a HTML document as a hierarchical tree structure.
HTML element: An object in the DOM, such as a paragraph, header, or title.
<p> and </p>.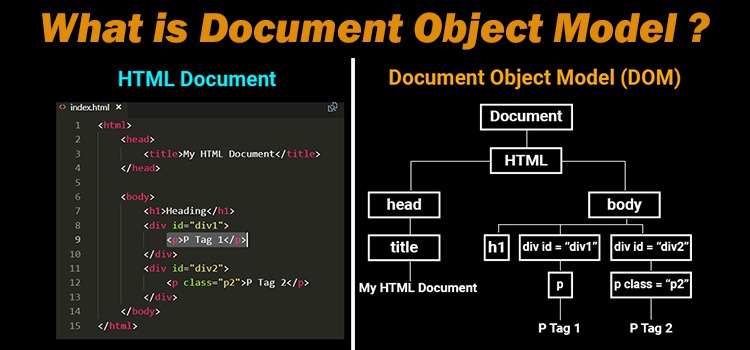
| Element | Description |
|---|---|
<html> |
the document |
<head> |
the header |
<body> |
the body |
<div> |
a logical division of the document |
<span> |
an inline logical division |
<p> |
a paragraph |
<a> |
an anchor (hyperlink) |
<h1>, <h2>, ... |
header(s) |
<img> |
an image |
There are many, many more. See this article for examples.
Tags can have attributes, which further specify how to display information on a webpage.
For instance, <img> tags have src and alt attributes (among others):
<img src="king-selfie.png" alt="A photograph of King Triton." width=500>
Hyperlinks have href attributes:
Click <a href="https://dsc80.com/project3">this link</a> to access Project 3.
What do you think this webpage looks like?
!cat data/lec15_ex2.html
<html>
<head>
<title>Project 3 - DSC 80, Winter 2023</title>
<link href="https://cdn.jsdelivr.net/npm/bootstrap@5.3.0-alpha1/dist/css/bootstrap.min.css" rel="stylesheet" integrity="sha384-GLhlTQ8iRABdZLl6O3oVMWSktQOp6b7In1Zl3/Jr59b6EGGoI1aFkw7cmDA6j6gD" crossorigin="anonymous">
</head>
<body>
<h1>Project Overview</h1>
<img src="../imgs/platter.png" width="200" alt="My dinner last night.">
<p>Start Project 3 by cloning our <a href="https://github.com/dsc-courses/dsc80-2023-wi/">public GitHub repo</a>.
Note that there is <b>no checkpoint</b> for Project 3!
</p>
<center><h3>Note that you'll have to submit your notebook as a PDF and a link to your website.</h3></center>
</body>
</html>
<div> tag¶<div style="background-color:lightblue">
<h3>This is a heading</h3>
<p>This is a paragraph.</p>
</div>
The <div> tag defines a division or a "section" of an HTML document.
<div> as a "cell" in a Jupyter Notebook.The <div> element is often used as a container for other HTML elements to style them with CSS or to perform operations involving them using JavaScript.
<div> elements often have attributes, which are important when scraping!
Under the document object model (DOM), HTML documents are trees. In DOM trees, child nodes are ordered.
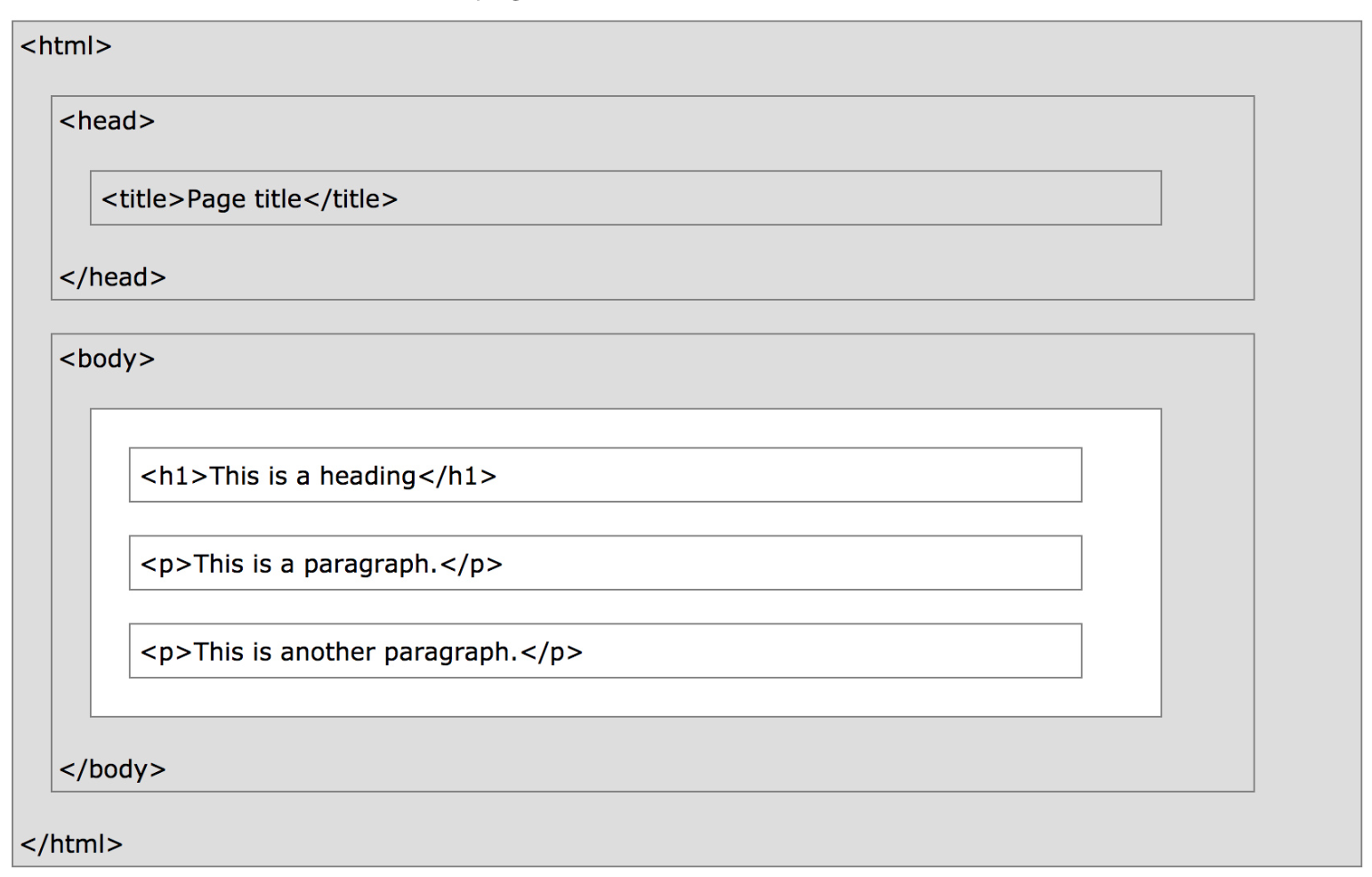
What does the DOM tree look like for this document?
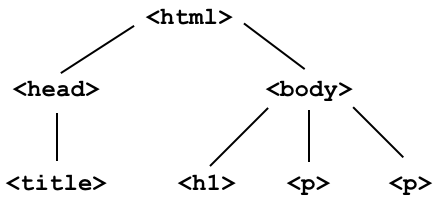
Consider the following webpage.


To start, we'll work with the source code for an HTML page with the DOM tree shown below:
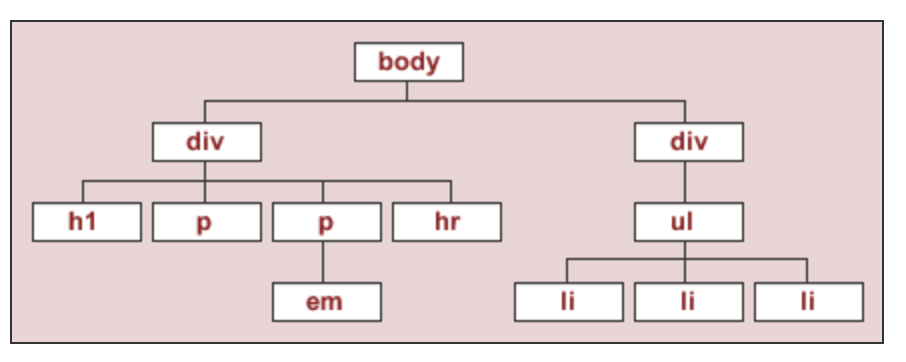
The string html_string contains an HTML "document".
html_string = '''
<html>
<body>
<div id="content">
<h1>Heading here</h1>
<p>My First paragraph</p>
<p>My <em>second</em> paragraph</p>
<hr>
</div>
<div id="nav">
<ul>
<li>item 1</li>
<li>item 2</li>
<li>item 3</li>
</ul>
</div>
</body>
</html>
'''.strip()
HTML(html_string)
My First paragraph
My second paragraph
BeautifulSoup objects¶bs4.BeautifulSoup takes in a string or file-like object representing HTML (markup) and returns a parsed document.
import bs4
bs4.BeautifulSoup?
Normally, we pass the result of a GET request to bs4.BeautifulSoup, but here we will pass our hand-crafted html_string.
soup = bs4.BeautifulSoup(html_string)
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
type(soup)
bs4.BeautifulSoup
BeautifulSoup objects have several useful attributes, e.g. text:
print(soup.text)
Heading here My First paragraph My second paragraph item 1 item 2 item 3
descendants¶The descendants attribute traverses a BeautifulSoup tree using depth-first traversal.
Why depth-first? Elements closer to one another on a page are more likely to be related than elements further away.
soup.descendants
<generator object Tag.descendants at 0x7fb91bf05d60>
for child in soup.descendants:
# print(child) # What would happen if we ran this instead?
if isinstance(child, str):
continue
print(child.name)
html body div h1 p p em hr div ul li li li
Practically speaking, you will not use the descendants attribute (or the related children attribute) directly very often. Instead, you will use the following methods:
soup.find(tag), which finds the first instance of a tag (the first one on the page, i.e. the first one that DFS sees).soup.find(name=None, attrs={}, recursive=True, text=None, **kwargs).soup.find_all(tag) will find all instances of a tag.soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
div = soup.find('div')
div
<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>
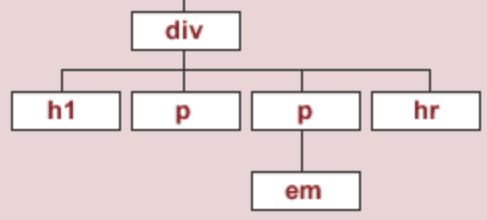
Let's try and find the <div> element that has an id attribute equal to 'nav'.
soup.find('div', attrs={'id': 'nav'})
<div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>
find will return the first occurrence of a tag, regardless of its depth in the tree.
soup.find('ul')
<ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul>
soup.find('li')
<li>item 1</li>
find_all¶find_all returns a list of all matches.
soup.find_all('div')
[<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>, <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div>]
soup.find_all('li')
[<li>item 1</li>, <li>item 2</li>, <li>item 3</li>]
[x.text for x in soup.find_all('li')]
['item 1', 'item 2', 'item 3']
text attribute of a tag element gets the text between the opening and closing tags.attrs attribute lists all attributes of a tag.get(key) method gets the value of a tag attribute.soup.find('p')
<p>My First paragraph</p>
soup.find('p').text
'My First paragraph'
soup.find('div')
<div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div>
soup.find('div').attrs
{'id': 'content'}
soup.find('div').get('id')
'content'
The get method must be called directly on the node that contains the attribute you're looking for.
soup
<html> <body> <div id="content"> <h1>Heading here</h1> <p>My First paragraph</p> <p>My <em>second</em> paragraph</p> <hr/> </div> <div id="nav"> <ul> <li>item 1</li> <li>item 2</li> <li>item 3</li> </ul> </div> </body> </html>
# While there are multiple 'id' attributes, none of them are in the <html> tag at the top.
soup.get('id')
soup.find('div').get('id')
'content'
.json() method of a response object or the json package to parse them, not eval.soup.find and soup.find_all are the functions you will use most often.