The wolf classifier¶
Below, we present a confusion matrix, which summarizes the four possible outcomes of the wolf classifier.

import pandas as pd
import numpy as np
import os
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.graph_objects as go
pd.options.plotting.backend = 'plotly'
TEMPLATE = 'seaborn'
import warnings
warnings.simplefilter('ignore')
Repeat the previous paragraph many, many times.
One night, the shepherd boy sees a real wolf approaching the flock and calls out, "Wolf!" The villagers refuse to be fooled again and stay in their houses. The hungry wolf turns the flock into lamb chops. The town goes hungry. Panic ensues.
Some questions to think about:
Below, we present a confusion matrix, which summarizes the four possible outcomes of the wolf classifier.
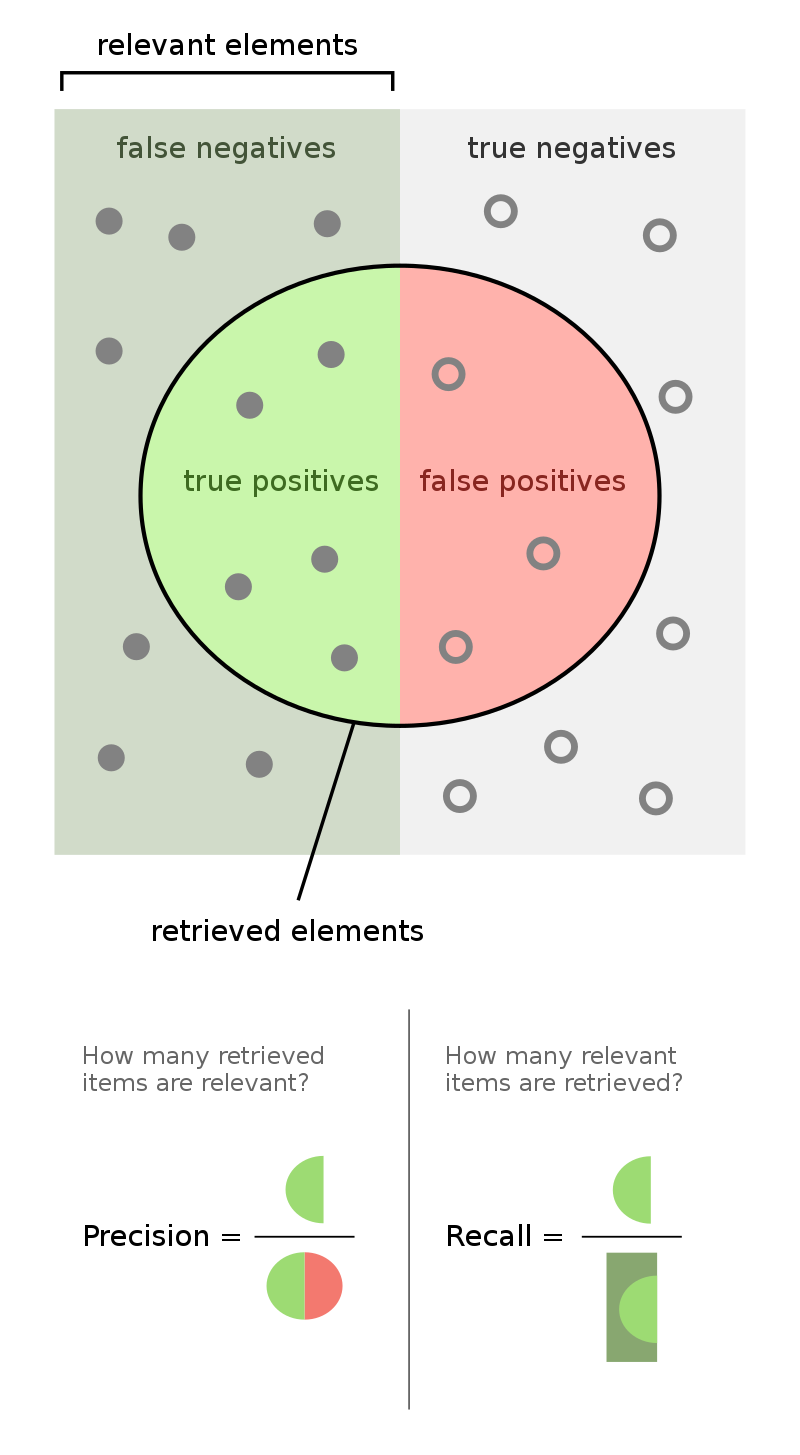
When performing binary classification, there are four possible outcomes.
(Note: A "positive prediction" is a prediction of 1, and a "negative prediction" is a prediction of 0.)
| Outcome of Prediction | Definition | True Class |
|---|---|---|
| True positive (TP) ✅ | The predictor correctly predicts the positive class. | P |
| False negative (FN) ❌ | The predictor incorrectly predicts the negative class. | P |
| True negative (TN) ✅ | The predictor correctly predicts the negative class. | N |
| False positive (FP) ❌ | The predictor incorrectly predicts the positive class. | N |
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN ✅ | FP ❌ |
| Actually Positive | FN ❌ | TP ✅ |
sklearn's confusion matrices are (but differently than in the wolf example).Note that in the four acronyms – TP, FN, TN, FP – the first letter is whether the prediction is correct, and the second letter is what the prediction is.
The results of 100 UCSD Health COVID tests are given below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 90 ✅ | FP = 1 ❌ |
| Actually Positive | FN = 8 ❌ | TP = 1 ✅ |
🤔 Question: What is the accuracy of the test?
🙋 Answer: $$\text{accuracy} = \frac{TP + TN}{TP + FP + FN + TN} = \frac{1 + 90}{100} = 0.91$$
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 90 ✅ | FP = 1 ❌ |
| Actually Positive | FN = 8 ❌ | TP = 1 ✅ |
🤔 Question: What proportion of individuals who actually have COVID did the test identify?
🙋 Answer: $\frac{1}{1 + 8} = \frac{1}{9} \approx 0.11$
More generally, the recall of a binary classifier is the proportion of actually positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{recall} = \frac{TP}{\text{# actually positive}} = \frac{TP}{TP + FN}$$To compute recall, look at the bottom (positive) row of the above confusion matrix.
🤔 Question: Can you design a "COVID test" with perfect recall?
🙋 Answer: Yes – just predict that everyone has COVID!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
Like accuracy, recall on its own is not a perfect metric. Even though the classifier we just created has perfect recall, it has 91 false positives!
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 0 ✅ | FP = 91 ❌ |
| Actually Positive | FN = 0 ❌ | TP = 9 ✅ |
The precision of a binary classifier is the proportion of predicted positive instances that are correctly classified. We'd like this number to be as close to 1 (100%) as possible.
$$\text{precision} = \frac{TP}{\text{# predicted positive}} = \frac{TP}{TP + FP}$$To compute precision, look at the right (positive) column of the above confusion matrix.
🤔 Question: When might high precision be more important than high recall?
🙋 Answer: For instance, in deciding whether or not someone committed a crime. Here, false positives are really bad – they mean that an innocent person is charged!
🤔 Question: When might high recall be more important than high precision?
🙋 Answer: For instance, in medical tests. Here, false negatives are really bad – they mean that someone's disease goes undetected!
Consider the confusion matrix shown below.
| Predicted Negative | Predicted Positive | |
|---|---|---|
| Actually Negative | TN = 22 ✅ | FP = 2 ❌ |
| Actually Positive | FN = 23 ❌ | TP = 18 ✅ |
What is the accuracy of the above classifier? The precision? The recall?
After calculating all three on your own, click below to see the answers.
The Wisconsin breast cancer dataset (WBCD) is a commonly-used dataset for demonstrating binary classification. It is built into sklearn.datasets.
from sklearn.datasets import load_breast_cancer
loaded = load_breast_cancer() # explore the value of `loaded`!
data = loaded['data']
labels = 1 - loaded['target']
cols = loaded['feature_names']
bc = pd.DataFrame(data, columns=cols)
bc.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst radius | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | ... | 25.38 | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | ... | 24.99 | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | ... | 23.57 | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | ... | 14.91 | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | ... | 22.54 | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 |
5 rows × 30 columns
1 stands for "malignant", i.e. cancerous, and 0 stands for "benign", i.e. safe.
labels[:5]
array([1, 1, 1, 1, 1])
pd.Series(labels).value_counts(normalize=True)
0 0.627417 1 0.372583 dtype: float64
Our goal is to use the features in bc to predict labels.
Logistic regression is a linear classification? technique that builds upon linear regression. It models the probability of belonging to class 1, given a feature vector:
$$P(y = 1 | \vec{x}) = \sigma (\underbrace{w_0 + w_1 x^{(1)} + w_2 x^{(2)} + ... + w_d x^{(d)}}_{\text{linear regression model}})$$Here, $\sigma(t) = \frac{1}{1 + e^{-t}}$ is the sigmoid function; its outputs are between 0 and 1 (which means they can be interpreted as probabilities).
🤔 Question: Suppose our logistic regression model predicts the probability that a tumor is malignant is 0.75. What class do we predict – malignant or benign? What if the predicted probability is 0.3?
🙋 Answer: We have to pick a threshold (e.g. 0.5)!
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
X_train, X_test, y_train, y_test = train_test_split(bc, labels)
clf = LogisticRegression()
clf.fit(X_train, y_train)
LogisticRegression()
How did clf come up with 1s and 0s?
clf.predict(X_test)
array([0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 0, 1,
0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1, 0, 0,
0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1,
1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0,
0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 0, 0, 1,
0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1,
1, 1, 0, 1, 0, 1, 0, 1, 0, 1, 1])
It turns out that the predicted labels come from applying a threshold of 0.5 to the predicted probabilities. We can access the predicted probabilities via the predict_proba method:
# [:, 1] refers to the predicted probabilities for class 1
clf.predict_proba(X_test)[:, 1]
array([7.94295847e-03, 1.46508816e-01, 9.99999997e-01, 9.99954498e-01,
4.13257030e-01, 1.84653899e-01, 9.99998202e-01, 9.98396980e-01,
1.20720076e-03, 5.03688766e-02, 1.78065609e-04, 9.99999991e-01,
1.74680950e-03, 6.99313832e-02, 1.09945386e-03, 9.96065915e-01,
9.99999950e-01, 1.08488649e-03, 9.99999972e-01, 4.64785992e-03,
3.00927020e-02, 1.00000000e+00, 9.21777820e-02, 1.00745636e-03,
1.16759247e-03, 7.24250513e-02, 9.99999993e-01, 6.29028933e-03,
6.75439478e-04, 2.52314469e-03, 1.82129441e-01, 5.57040347e-01,
2.13389091e-02, 9.99999637e-01, 7.09681255e-02, 4.44550849e-01,
7.31031677e-01, 4.92595026e-04, 9.13457244e-01, 2.18146486e-02,
1.73094215e-02, 9.99975715e-01, 4.22927990e-03, 1.95620837e-02,
2.76976251e-02, 9.99904502e-01, 1.76698618e-01, 9.94687649e-01,
9.25924022e-01, 5.48363657e-03, 3.13756644e-03, 9.36500303e-04,
7.55250968e-03, 9.99999469e-01, 9.99995717e-01, 6.17836908e-03,
9.68038110e-01, 1.00000000e+00, 2.11513716e-01, 1.36351721e-03,
2.68424947e-02, 9.98504617e-01, 2.70892900e-01, 1.01721784e-03,
1.26726451e-03, 1.00000000e+00, 9.95653635e-01, 2.38257620e-04,
9.99999010e-01, 9.72212548e-03, 2.86611109e-01, 9.88800477e-01,
9.99999999e-01, 1.48769628e-04, 2.20729638e-02, 9.99984878e-01,
2.75345816e-02, 9.15021234e-03, 8.32426049e-03, 1.09860291e-03,
9.99999989e-01, 9.80904304e-01, 1.07950649e-03, 1.31958411e-02,
9.99999921e-01, 9.99999050e-01, 9.38069197e-03, 2.49194390e-02,
5.11939601e-02, 9.63046935e-04, 9.98890289e-01, 1.00000000e+00,
9.99999545e-01, 6.02546077e-03, 1.94085839e-02, 9.99998227e-01,
9.76964995e-01, 1.78696336e-02, 1.00988736e-02, 9.99999986e-01,
4.74230640e-03, 9.98478581e-01, 9.99908847e-01, 6.75316368e-02,
9.99976657e-01, 9.99997315e-01, 1.00000000e+00, 3.57766588e-03,
2.44101789e-03, 9.99999998e-01, 1.49899499e-02, 2.98130818e-03,
1.00000000e+00, 2.38539359e-04, 9.18786758e-01, 1.08825220e-01,
5.37416143e-03, 9.99997173e-01, 9.99999997e-01, 1.90787955e-03,
2.05531085e-02, 9.72676221e-01, 4.42192973e-01, 2.18528054e-01,
3.06996055e-03, 9.70114955e-01, 1.61008965e-02, 1.41685606e-01,
6.40011642e-03, 2.08208427e-03, 8.57716856e-02, 1.00000000e+00,
9.19285643e-01, 9.99982630e-01, 1.13326535e-01, 1.00000000e+00,
3.23501951e-04, 9.99178419e-01, 1.66014296e-02, 1.00000000e+00,
1.40825512e-01, 8.73730382e-01, 6.44518685e-01])
Note that our model still has $w^*$s:
clf.intercept_
array([-0.15333688])
clf.coef_
array([[-0.91122427, -0.52637545, -0.30687707, 0.02322356, 0.03324291,
0.16346268, 0.21743892, 0.08952366, 0.05609724, 0.01164223,
-0.03633486, -0.34178678, -0.0807604 , 0.10246104, 0.00394736,
0.03622608, 0.0453615 , 0.01110168, 0.01553456, 0.00294386,
-0.93175552, 0.53801531, 0.24392027, 0.0105438 , 0.06384033,
0.49372508, 0.57528102, 0.16599722, 0.17487266, 0.04547537]])
Let's see how well our model does on the test set.
from sklearn import metrics
y_pred = clf.predict(X_test)
metrics.accuracy_score(y_test, y_pred)
0.9300699300699301
metrics.precision_score(y_test, y_pred)
0.9491525423728814
metrics.recall_score(y_test, y_pred)
0.8888888888888888
Which metric is more important for this task – precision or recall?
metrics.confusion_matrix(y_test, y_pred)
array([[77, 3],
[ 7, 56]])
metrics.plot_confusion_matrix(clf, X_test, y_test)
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7fb4128043a0>

🤔 Question: Suppose we choose a threshold higher than 0.5. What will happen to our model's precision and recall?
🙋 Answer: Precision will increase, while recall will decrease*.
Similarly, if we decrease our threshold, our model's precision will decrease, while its recall will increase.
The classification threshold is not actually a hyperparameter of LogisticRegression, because the threshold doesn't change the coefficients ($w^*$s) of the logistic regression model itself (see this article for more details).
As such, if we want to imagine how our predicted classes would change with thresholds other than 0.5, we need to manually threshold.
thresholds = np.arange(0, 1.01, 0.01)
precisions = np.array([])
recalls = np.array([])
for t in thresholds:
y_pred = clf.predict_proba(X_test)[:, 1] >= t
precisions = np.append(precisions, metrics.precision_score(y_test, y_pred))
recalls = np.append(recalls, metrics.recall_score(y_test, y_pred))
Let's visualize the results in plotly, which is interactive.
px.line(x=thresholds, y=precisions,
labels={'x': 'Threshold', 'y': 'Precision'}, title='Precision vs. Threshold', width=1000, height=600,
template=TEMPLATE)
px.line(x=thresholds, y=recalls,
labels={'x': 'Threshold', 'y': 'Recall'}, title='Recall vs. Threshold', width=1000, height=600,
template=TEMPLATE)
px.line(x=recalls, y=precisions, hover_name=thresholds,
labels={'x': 'Recall', 'y': 'Precision'}, title='Precision vs. Recall',
template=TEMPLATE)
The above curve is called a precision-recall (or PR) curve.
🤔 Question: Based on the PR curve above, what threshold would you choose?
If we care equally about a model's precision $PR$ and recall $RE$, we can combine the two using a single metric called the F1-score:
$$\text{F1-score} = \text{harmonic mean}(PR, RE) = 2\frac{PR \cdot RE}{PR + RE}$$pr = metrics.precision_score(y_test, clf.predict(X_test))
re = metrics.recall_score(y_test, clf.predict(X_test))
2 * pr * re / (pr + re)
0.9180327868852458
metrics.f1_score(y_test, clf.predict(X_test))
0.9180327868852458
Both F1-score and accuracy are overall measures of a binary classifier's performance. But remember, accuracy is misleading in the presence of class imbalance, and doesn't take into account the kinds of errors the classifier makes.
metrics.accuracy_score(y_test, clf.predict(X_test))
0.9300699300699301
We just scratched the surface! This excellent table from Wikipedia summarizes the many other metrics that exist.

If you're interested in exploring further, a good next metric to look at is true negative rate (i.e. specificity), which is the analogue of recall for true negatives.
Quantifying the fairness of predictive models. Conclusion.